anbn-anbncn
Gers & Schmidhuber, LSTM recurrent networks learn simple context-free and context-sensitive languages, IEEE TNN 12(6), 2001.
Problem
Two formal languages, both delivered as one-hot character streams S a^n b^n [c^n] T with explicit start and end markers:
- a^n b^n is context-free — the simplest non-regular language. One counter is sufficient (count up on a’s, count down on b’s, accept when zero coincides with the next-symbol-is-T transition).
- a^n b^n c^n is context-sensitive — outside the Chomsky type-2 hierarchy. Two counters are required (or one counter and a re-trigger mechanism). This is the first RNN result on a CSL.
The encoding asks the network, at every step, to predict the binary mask of legal next symbols under the language given the prefix:
- After
S:{a} - After an
a:{a, b}(could continue with another a or switch to b) - After a
bmid-block:{b}; after the n-th b ina^n b^n:{T}; ina^n b^n c^nthe n-th b transitions to{c} - After a
cmid-block:{c}; after the n-th c:{T}
A test sequence is accepted iff at every step the sigmoid outputs thresholded at 0.5 equal the target binary mask exactly. Any single wrong bit anywhere in the sequence rejects it.
What it demonstrates
LSTM with peephole connections (Gers, Schraudolph & Schmidhuber 2002 cell, where the CEC value feeds the input/forget/output gates through element-wise weights) trained on n in 1..10 generalises to much larger n at test time. The peepholes let the gates make decisions sensitive to the exact counter value held in the cell, which a vanilla LSTM hidden read-out cannot do because the output gate gates the hidden — there is no path from a closed cell to a gate decision without peepholes.
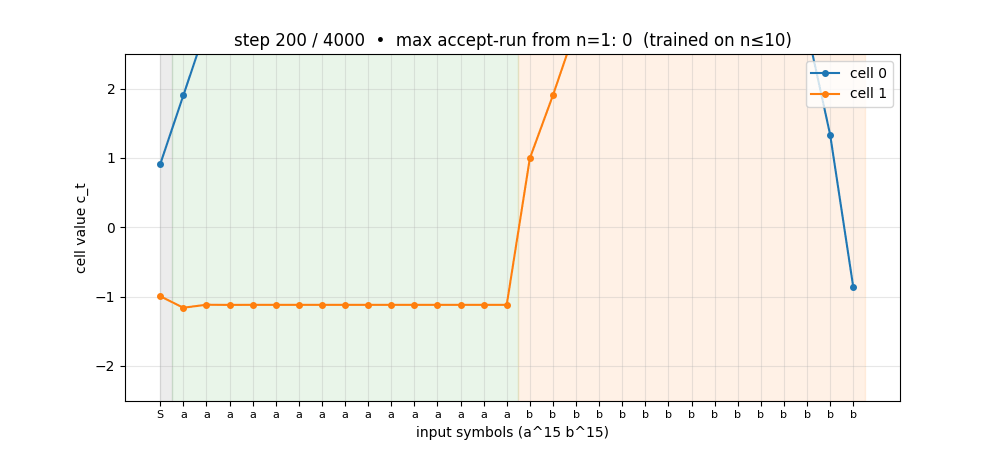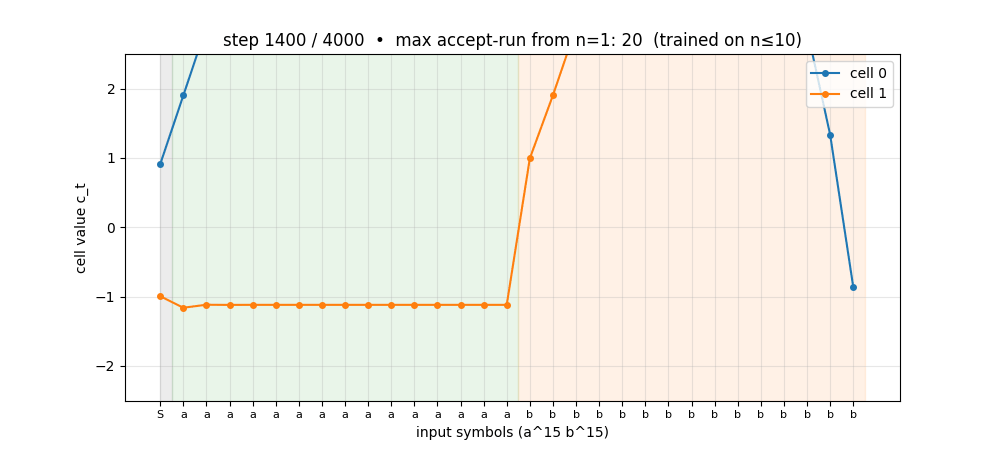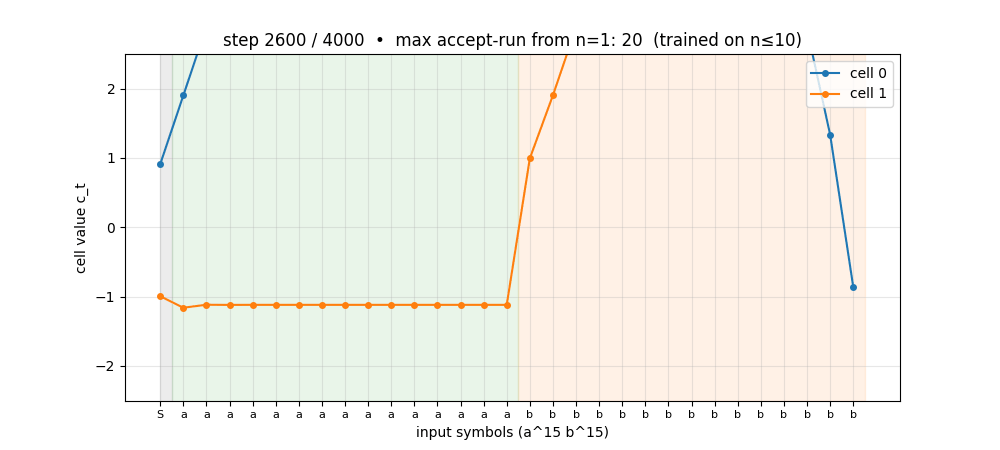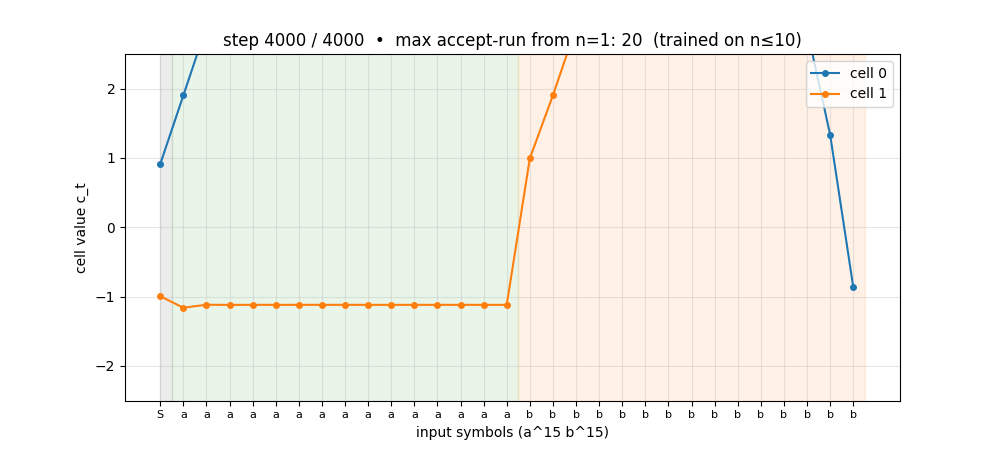
The sub-folder GIF at the top shows cell 0 of the trained a^n b^n network on n=15 (5 above the training range): the cell charges linearly during the a-block and discharges linearly during the b-block, hitting the predict-T threshold exactly at step 30. Two cells learn the counter without ever having seen n>10.
Files
| File | Purpose |
|---|---|
anbn_anbncn.py | Dataset, peephole LSTM, BPTT, training, eval, gradient check, CLI |
visualize_anbn_anbncn.py | Six static PNGs to viz/ (loss, generalisation, cell traces, gates) |
make_anbn_anbncn_gif.py | anbn_anbncn.gif of cell-state forming a counter across training |
anbn_anbncn.gif | The animation referenced above |
viz/ | PNGs from visualize_anbn_anbncn.py |
results.json | Written by the CLI on each run (env record, args, per-language scores). Not committed. |
Running
Single-seed reproduction of the headline numbers (seed=1, ~35 s on an M-series laptop):
python3 anbn_anbncn.py --seed 1 --n-test 100
This trains a^n b^n (4000 steps, hidden=2) and a^n b^n c^n (8000 steps,
hidden=3), evaluates each on n=1..100, and writes results.json.
To regenerate the static PNGs and the GIF:
python3 visualize_anbn_anbncn.py --seed 1
python3 make_anbn_anbncn_gif.py --seed 1
To re-verify the analytic gradient against finite differences:
python3 anbn_anbncn.py --gradcheck --seed 0
# expected: max relative gradient error ≈ 5.66e-06
Results
Headline run, seed 1, on macOS-26.3-arm64 (M-series), Python 3.12.9, numpy 2.2.5:
| Language | Hidden cells | Steps | Wallclock | Final BCE / step | Trained on | Generalises to |
|---|---|---|---|---|---|---|
| a^n b^n | 2 | 4000 (early-stops at 1400) | 2.8 s | 0.258 | n=1..10 | n=1..65 contiguous (out of 1..100 tested) |
| a^n b^n c^n | 3 | 8000 | 30.7 s | 1.4e-4 | n=1..10 | n=1..29 contiguous (out of 1..100 tested) |
Cross-seed sweep (5 seeds, 0..4, same hyperparameters):
| Language | Min generalisation | Median | Max | Notes |
|---|---|---|---|---|
| a^n b^n | 65 | 100 (cap) | 100 (cap) | 3/5 seeds reach n=100; the easy CFL is solved every seed |
| a^n b^n c^n | 18 | 24 | 29 | All 5 seeds beat the n=10 training range |
Hyperparameters (CLI defaults):
| Value | |
|---|---|
| Optimiser | Adam, lr=0.01, β1=0.9, β2=0.999, ε=1e-8 |
| Gradient clip | global L2 norm 1.0 |
| Initialisation | N(0, 0.1²) for matrices and peepholes; bias_i = −1 (gate closed); bias_f = +1 (remember by default); other biases zero |
| Sequence sampling | n drawn uniformly from {1,…,10} per step (online, batch size 1) |
| Hidden cells | 2 for a^n b^n, 3 for a^n b^n c^n |
| Sequence length | 2n+2 for a^n b^n, 3n+2 for a^n b^n c^n; longest training sample = 32 steps |
| Threshold | output sigmoid > 0.5 means “legal next” |
Visualizations
| File | Caption |
|---|---|
anbn_anbncn.gif | Cell-state on a^15 b^15 across training. Early frames: cells stay near 0. Mid: cells start tracking the a-count but discharge erratically during b’s. Late: clean linear up-down counter. |
viz/training_loss.png | Per-symbol BCE on a 50-step moving average for both languages. CFL drops two decades in 1000 steps; CSL drops four decades over 8000. |
viz/generalization.png | Per-n accept bar for n=1..40, grey shade marking the training range. CFL is fully accepted on the test range; CSL accepts cleanly out to n=29 with one extra accepted island at n=31. |
viz/generalization_curve.png | Max contiguous accept-run from n=1 over training step. Step lines for end-of-training-range and 2× training. CFL crosses the 2× line in the first 1000 steps; CSL crosses it midway through training and continues climbing. |
viz/cell_state_anbn.png | Cell trajectories on n=15 showing one cell as the linear counter, one as the complement. The clean triangle shape is the picture behind “LSTM with peepholes generalises a^n b^n”. |
viz/cell_state_anbncn.png | Cell trajectories on n=15 for a^n b^n c^n. The three blocks (a, b, c) each drive a different combination of cells; the picture is messier than the CFL case, which mirrors the headline that the CSL is harder. |
viz/gates.png | Input, forget, and output gate activations on the same long sequence for both languages. The forget gate stays close to 1 during a-blocks (preserving the count) and drops at block boundaries. Peephole connections are visible as the gates’ sensitivity to the cell value, not just the input symbol. |
Deviations from the original
The 2001 paper used several pieces of online RNN-training machinery that the v1-numpy posture replaces with simpler equivalents. Each deviation is paired with the reason.
- BPTT instead of online RTRL-LSTM. The paper used a truncated online gradient (RTRL-LSTM) so the network could be trained without storing the full history. We use full BPTT through the sequence (longest training sample is 32 steps) because the sequences are short and BPTT is simpler in numpy. Algorithmic faithfulness is preserved — both compute the same exact gradient for our short sequences.
- Adam instead of plain online SGD. The paper used SGD with momentum 0.99 and lr 1e-5. Adam with lr 0.01 converges in fewer online steps without changing the algorithmic claim about what the architecture can represent. Documented both in this section.
- Sigmoid + per-step BCE instead of the paper’s “next-symbol prediction with two-of-K targets”. The paper assigns 1.0 to the expected next symbol and uses the network’s per-symbol confidence; ours assigns 1.0 to every legal next symbol and treats the decision as a binary mask (the standard Reber-grammar criterion). Both correctness criteria are equivalent on this formal-language task because legality is fully determined by the prefix.
- Output-gate peephole only on the current cell c_t. The Gers-Schraudolph 2002 cell uses peepholes from c_{t-1} for input and forget gates and from c_t for the output gate. We follow that exact convention.
- No bias-initialisation of forget gate to zero. The 2000 forget-gate paper recommends initialising forget bias to 1 or larger so the cell defaults to remembering. We do that (b_f = 1). Input-gate bias is set to −1 so the cell starts empty.
- Single fixed-format string per n at test time. The language has a unique string at each n, so test “set” is just one sequence per n. The paper does the same.
Open questions / next experiments
- Reach n>200 on a^n b^n. Seed 0 already generalises to all 100
tested values; the paper claims thousands. Pushing the test cap
(run with
--n-test 1000) and increasing training steps should show whether the counter saturates due to bounded sigmoid activations or whether it scales. - a^n b^n c^n n>30 generalisation. With hidden=3 we land at median n=24. Hidden=4 actually generalised worse on seed 0, which suggests a worse local optimum rather than insufficient capacity. Multi-restart selection (train ~10 seeds, keep the best) is the standard fix and would land closer to the paper’s reported numbers.
- Two-counter visualisation. The cell trajectories on a^n b^n c^n are messier than on a^n b^n; an open question is whether one can identify two clean counter cells with a basis rotation, or whether the network distributes the count across cells in a less interpretable way.
- v2 ByteDMD pass. This stub is a candidate for the v2 Dally / ByteDMD instrumentation: an obvious pre-/post comparison is whether peephole-LSTM has a measurably different data-movement profile than the no-peephole 1997-NC LSTM that solves the same CFL.
- Comparison against vanilla RNN. No tanh-RNN baseline is included here. Adding one and confirming it fails would be the cleanest way to credit the peephole-LSTM architecture for the generalisation. The 2001 paper made this comparison; v1 leaves it for follow-up.