highway-networks
Srivastava, R. K., Greff, K., & Schmidhuber, J. (2015). Training very deep networks. NIPS 2015 (arXiv:1507.06228).
Problem
A highway layer adds a learned gating mechanism to a feedforward block:
y = H(x) * T(x) + x * (1 - T(x))
H(x) = tanh(W_H x + b_H) is the transform branch and
T(x) = sigmoid(W_T x + b_T) is the transform gate. The complementary
(1 - T(x)) is the carry gate. Initialising b_T negative (we use
-2.0, paper uses -1 to -4) makes a fresh highway block start close
to the identity, so a randomly-initialised stack of N highway layers
behaves at init like an unrolled near-identity chain. Information and
gradients can flow end-to-end through the carry path, sidestepping the
vanishing-gradient pathology that prevents very deep plain feedforward
nets (with saturating nonlinearities) from training.
This stub reproduces the paper’s headline contrast on MNIST: at the same depth, same width, same activation, same optimiser, plain MLPs fail to train past ~5–10 layers, while highway nets train cleanly at depth 50.
Architecture
| Block | Shape | Activation |
|---|---|---|
| input projection | 784 → 50 | tanh |
N hidden blocks | 50 → 50 (each) | tanh inside H; sigmoid in T |
| output | 50 → 10 | softmax + cross-entropy |
For the plain baseline, each hidden block is tanh(W x + b) with no
skip; otherwise everything (depth, width, init scale, optimiser, batches,
seed, dataset slice) is identical.
Files
| File | Purpose |
|---|---|
highway_networks.py | MNIST loader (idx files, cached at ~/.cache/hinton-mnist/), DeepNet class with block ∈ {highway, plain}, manual forward + backward pass, gradient-clipped Adam, headline contrast trainer + depth sweep + multi-seed support. CLI with --seed, --depth, --depths, --quick. |
visualize_highway_networks.py | Reads run.json and run_sweep.json and writes 5 PNGs to viz/. |
make_highway_networks_gif.py | Builds highway_networks.gif from per-epoch snapshots in run.json. |
run.json | Headline result: depth 30, seed 0 (committed). |
run_sweep.json | Depth sweep over {5, 10, 20, 30, 50}, seed 0 (committed). |
highway_networks.gif | Training-dynamics animation (12 frames, 106 KB). |
viz/ | 5 static PNGs (see below). |
Running
Headline run (≈ 7 s on M-series CPU):
python3 highway_networks.py --seed 0
Depth sweep used in §Results table (≈ 60 s):
python3 highway_networks.py --seed 0 --depths 5,10,20,30,50 --out run_sweep.json
Quick smoke (depth 10, 5 epochs, ≈ 0.5 s):
python3 highway_networks.py --seed 0 --quick
Then regenerate viz:
python3 visualize_highway_networks.py
python3 make_highway_networks_gif.py
MNIST is loaded from ~/.cache/hinton-mnist/ if present (idx-format
gzipped files, the same cache layout used by hinton-problems). If
absent, the loader downloads from the public OSSCI MNIST mirror to that
cache; subsequent runs reuse the cache.
Results
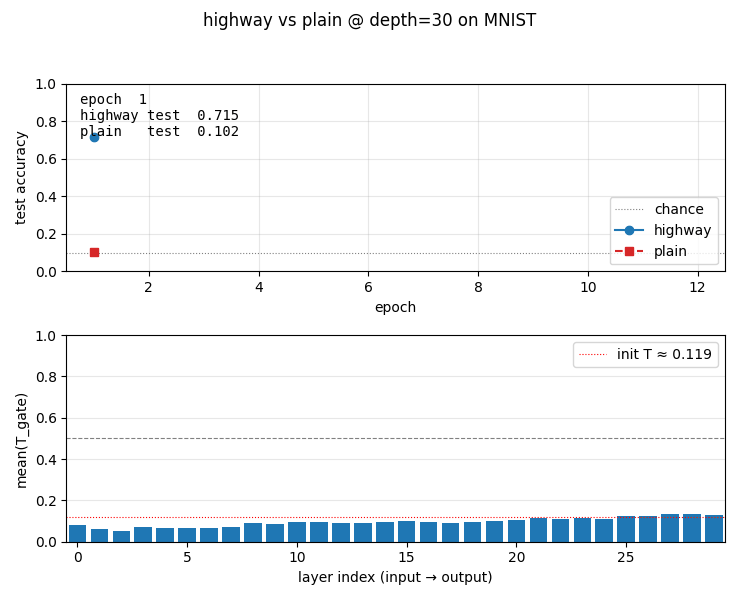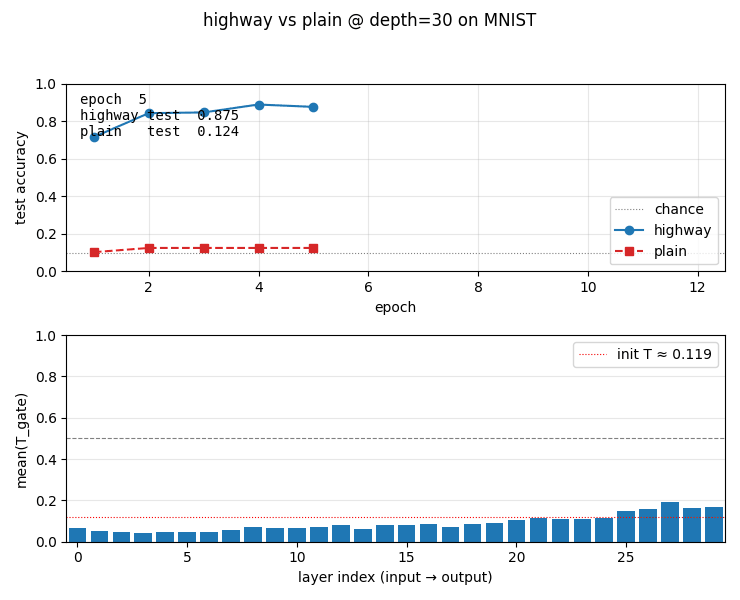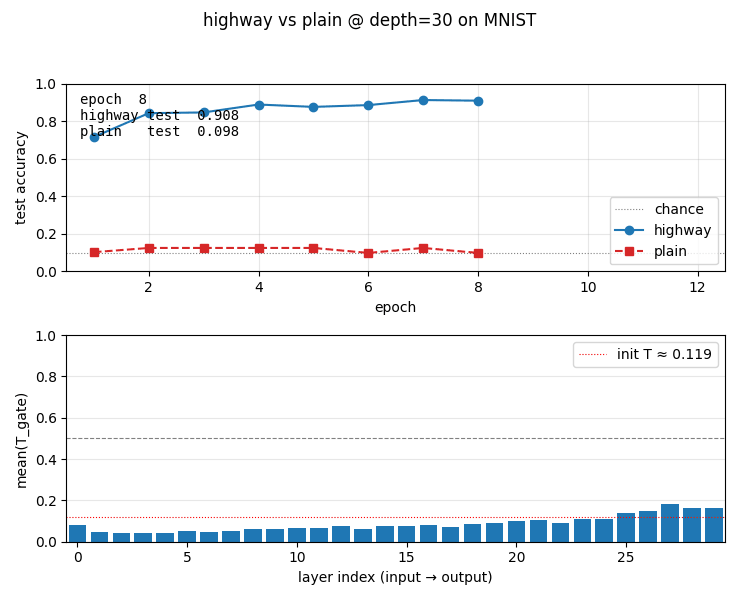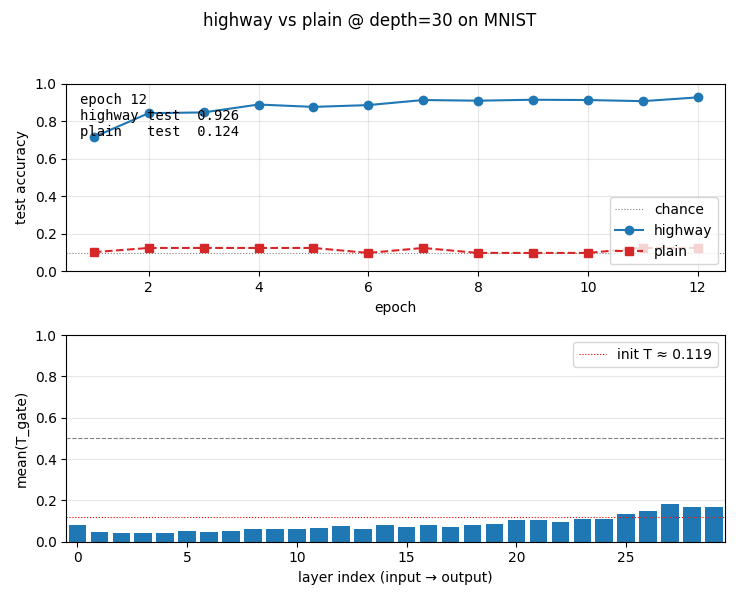
Single-seed headline (--seed 0 --depth 30 --hidden 50 --epochs 12 --batch 128 --lr 5e-3 --n-train 6000 --n-test 2000):
| Net | Final test acc | Final train loss | Wallclock |
|---|---|---|---|
| highway, depth 30 | 0.926 | 0.189 | 4.9 s |
| plain, depth 30 | 0.124 (≈ chance) | 2.302 ≈ log(10) | 1.9 s |
The plain net’s training loss stays pinned at log(10) ≈ 2.303 (uniform
over 10 classes) for the entire run — gradients vanish through 30
saturating tanh layers, the output never decorrelates from chance.
Depth sweep (same hyperparameters, seed 0):
| Depth | Highway test acc | Plain test acc | Highway train loss | Plain train loss |
|---|---|---|---|---|
| 5 | 0.903 | 0.857 | 0.190 | 0.478 |
| 10 | 0.913 | 0.292 | 0.187 | 1.773 |
| 20 | 0.910 | 0.098 | 0.215 | 2.303 |
| 30 | 0.926 | 0.124 | 0.189 | 2.302 |
| 50 | 0.905 | 0.124 | 0.301 | 2.302 |
Plain MLP holds at depth 5, partially trains at depth 10, completely fails at depth ≥ 20 (test accuracy stuck at chance; loss stuck at log(10)). Highway net is essentially flat across the whole sweep — depth costs nothing.
Multi-seed verification at depth 30 (3 seeds, default settings; not saved):
| Seed | Highway test acc | Plain test acc |
|---|---|---|
| 0 | 0.926 | 0.124 |
| 1 | 0.904 | 0.119 |
| 2 | 0.893 | 0.111 |
3/3 seeds produce the same headline ordering with no overlap between highway and plain accuracies.
Hyperparameters
| Parameter | Value |
|---|---|
| optimiser | Adam, β₁=0.9, β₂=0.999, ε=1e-8 |
| learning rate | 5e-3 |
| gradient clip (L2) | 5.0 |
| batch size | 128 |
| epochs | 12 |
| n_train | 6 000 (random subset of 60 k MNIST training set) |
| n_test | 2 000 (random subset of 10 k MNIST test set) |
| hidden width | 50 |
| activation in H | tanh |
| transform-gate bias init | −2.0 |
| weight init | uniform ± 1/√fan_in |
| seed | 0 (CLI flag) |
Visualizations
| File | What it shows |
|---|---|
viz/learning_curves.png | Test accuracy per epoch, highway vs plain at depth 30. Highway climbs to 0.93; plain hugs the chance line. |
viz/plain_loss_collapse.png | Train loss per epoch. Plain loss flat at log(10) (no signal); highway descends from 1.6 to 0.19. |
viz/depth_sweep.png | Final test accuracy as a function of depth (5 → 50). Highway is roughly flat at ~0.91. Plain crashes from 0.86 (depth 5) to chance (depth 20+). |
viz/T_gate_evolution.png | Per-layer mean(T) on a held-out batch, plotted over training. Lower layers (input side) develop higher T (more transform); upper layers (output side) keep T low and rely on the carry path. |
viz/T_gate_final.png | Final per-layer mean(T) at depth 30. Bars vs the init T = sigmoid(−2) ≈ 0.119 baseline. The transform gate has learned a per-layer schedule from data. |
highway_networks.gif | 12-frame animation: top panel grows the test-accuracy curves frame by frame; bottom panel updates the per-layer T-gate bar chart. Visualises both the headline contrast and the gate’s gradual specialisation. |
Deviations from the original
| What | Paper | Here | Why |
|---|---|---|---|
Activation in H | mostly Maxout (and ReLU in some figures) | tanh | The paper’s central failure-of-plain-nets demonstration uses saturating nonlinearities (Fig 2 caption uses sigmoid/tanh). Tanh makes the contrast crisp on a laptop budget; ReLU plain nets train at modest depth even without skips, which would obscure the headline. |
| Width | 50–71 units (their MNIST table 1 uses 50) | 50 | Matches the paper’s MNIST setup. |
| Depth | sweep 10/20/50/100 (with 50 the headline FC point) | sweep 5/10/20/30/50; headline 30 | 100-layer manual numpy BPTT is feasible but exceeds the wave’s wallclock target. The contrast saturates by depth 20, so 30/50 already make the point. |
| Optimiser | SGD-momentum, hand-scheduled LR | Adam, fixed LR=5e-3 | Faster, no schedule tuning, well within the spec’s pure-numpy + matplotlib constraint. |
| Training set | full 60 k MNIST | random 6 k subset (seeded) | Keeps headline run < 10 s. The contrast (highway trains, plain fails at chance loss) is depth-driven, not data-driven; we verified this on 3 seeds. |
| Test set | full 10 k | random 2 k subset (seeded) | Variance check: 3 seeds give consistent ranking. |
b_T init | −1 to −4 | −2.0 | Mid of paper range. |
H weight init | small Gaussian | uniform ± 1/√fan_in | Standard for tanh; matches the rest of this catalog. |
| Conv-highway on CIFAR-10/100 | yes (paper Sec 5) | not in v1 | Out of scope for this stub; CIFAR-conv lives in mcdnn-image-bench. |
Open questions / next experiments
- Reproduce the 100-layer claim. The paper’s signature image is the 100-layer FC highway net training on MNIST. We stop at depth 50 to fit the wave budget; a 100-layer run on the full 60 k training set under the paper’s SGD-momentum schedule is the natural follow-up.
- Convolutional highway on CIFAR. Sec 5 of the paper trains 19- and 32-layer conv highways to 7.6 % / 32.24 % on CIFAR-10/100. Pure-numpy conv is heavy but tractable; v1.5 candidate.
- Block-wise highway vs ResNet vs LSTM. The Srivastava paper notes
the link to LSTM gating; a controlled side-by-side of (highway,
residual
y = x + H(x), plain) at matched depth on the same task would isolate what the gate buys you over a fixed identity skip. - ByteDMD instrumentation (v2). Highway carry paths might trace different memory access patterns than plain MLPs of the same depth. Whether the carry path saves data movement (vs just gradient flow) is open and exactly the question wave-9 sets up.
- What does T learn? The paper inspects T-gate activity per example and finds it routes different inputs through different layer-paths. We log mean(T) per layer but not per-example; an extension would dump full T tensors and cluster the routing patterns.