pipe-symbolic-regression
Salustowicz & Schmidhuber, Probabilistic Incremental Program Evolution, Evolutionary Computation 5(2):123–141, 1997.
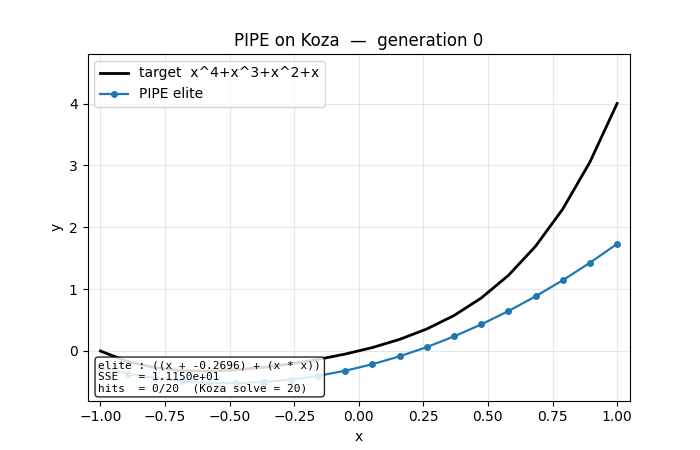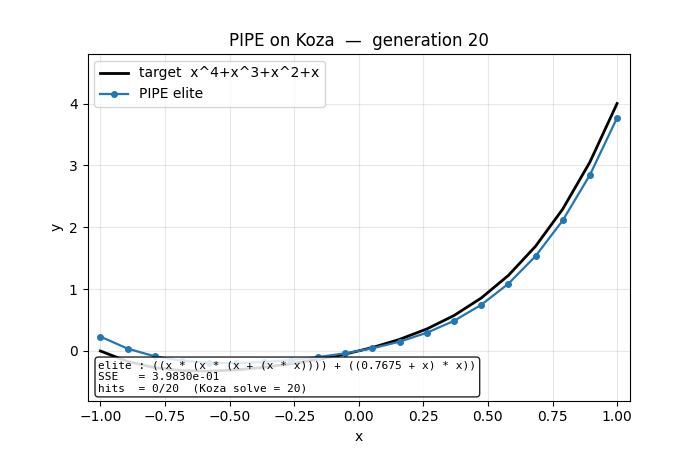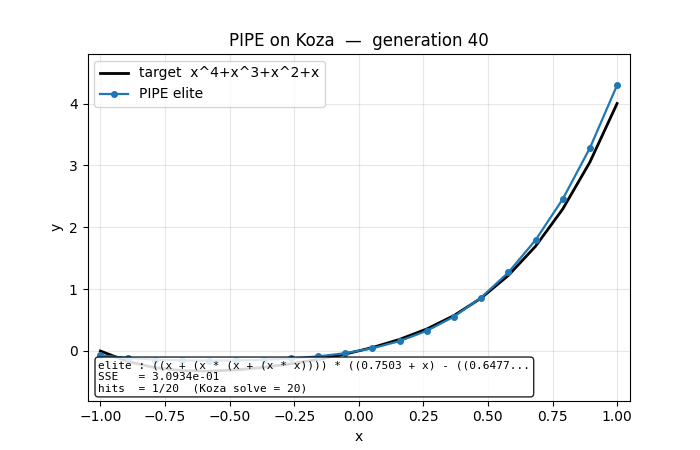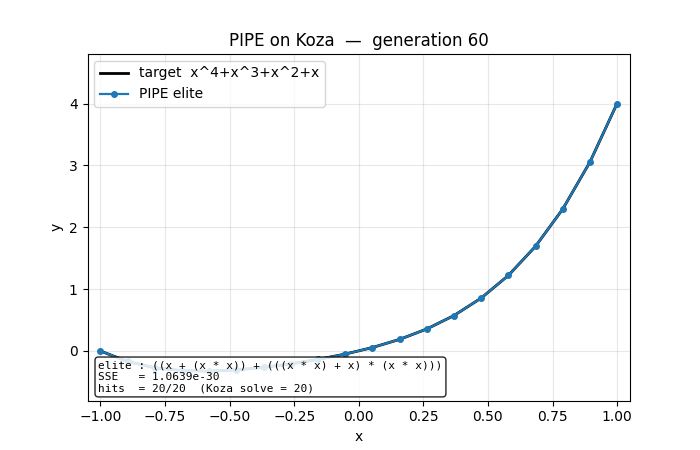
Problem
Symbolic regression on Koza’s classic benchmark target
f(x) = x^4 + x^3 + x^2 + x
evaluated on 20 fitness cases x ∈ linspace(-1, 1, 20). The instruction set is the one the original PIPE paper uses for this benchmark (Table 1, p. 134):
- function set:
{ +, −, *, / }(binary, protected division) - terminal set:
{ x, R }whereRis a node-local random constant.
A program is a tree of those symbols. A fitness case is “hit” iff
|f(x) − f̂(x)| < 0.01 (Koza’s hit criterion); 20/20 hits = problem
solved. Standardised fitness is 1 / (1 + SSE).
What it demonstrates
PIPE evolves programs without crossover. Instead it keeps a Probabilistic Prototype Tree (PPT) — a tree-shaped distribution over program syntax. Each generation:
- Sample N programs by descending the PPT from the root.
- Score them on the 20 fitness cases.
- Run a Population-Based Incremental Learning update at every
PPT node visited by the elite (best individual ever): nudge the
probability of the elite’s symbol up by
lr · P_TARGET · (1 − p)until p ≥P_TARGET, then re-normalise. - Mutate visited PPT nodes with per-symbol probability
P_M / (|I| · √n_visited), the schedule from §3 of the paper.
The headline at seed 3: PIPE rediscovers the exact polynomial
((x + x*x) + ((x*x + x) * x*x)) — which simplifies to
x + x^2 + x^3 + x^4 — at generation 60 in 1.3 s of CPU,
SSE = 1.06e-30, all 20 Koza fitness cases hit. The GIF above shows the
elite curve sliding from a poor initial guess to a perfect overlay of
the target.
Files
| File | Purpose |
|---|---|
pipe_symbolic_regression.py | PPT, sampling, fitness, PBIL update, mutation, training loop, CLI |
visualize_pipe_symbolic_regression.py | Static PNGs to viz/ (fitness, SSE log-curve, hits, fit overlay, size+depth, final scatter) |
make_pipe_symbolic_regression_gif.py | pipe_symbolic_regression.gif of elite fit over generations |
pipe_symbolic_regression.gif | The animation referenced above |
viz/ | PNGs from visualize_pipe_symbolic_regression.py |
results.json | Written on each CLI run (env, args, summary). Not committed. |
Running
Headline single-seed reproduction (seed 3, ≈1.3 s on an M-series laptop):
python3 pipe_symbolic_regression.py --seed 3
This trains for up to 200 generations of population 100 with the
arithmetic-only function set. With seed 3 PIPE crosses the 20/20-hits
line at generation 60 and the SSE < 1e-6 line at the same generation,
then exits. Pass --max-gen 300 --quiet to silence per-10-gen logging.
To regenerate static PNGs and the GIF:
python3 visualize_pipe_symbolic_regression.py --seed 3 --max-gen 200
python3 make_pipe_symbolic_regression_gif.py --seed 3 --max-gen 120
To try the larger function set hinted by the SPEC
({+,-,*,/,sin,cos,exp,log}):
python3 pipe_symbolic_regression.py --seed 3 --funcs full --max-gen 300
This converges more slowly because the search space is larger; see §Deviations.
Results
Headline run, seed 3, on macOS-26.3-arm64 (M-series), Python 3.11.10,
numpy 2.3.4, function set {+, −, *, /}:
| Quantity | Value |
|---|---|
| Discovered program | ((x + x*x) + ((x*x + x) * x*x)) |
| Simplifies to | x + x^2 + x^3 + x^4 ✓ |
| SSE on 20 cases | 1.06e-30 |
| Koza hits | 20 / 20 |
| Solved at gen | 60 |
| Wallclock | 1.31 s |
| Generations run | 61 |
| Elite tree size | 15 nodes |
| Elite tree depth | 5 |
Cross-seed sweep (20 seeds, 0..19, same hyperparameters, max 300 generations):
| Criterion | Successes / 20 | Seeds that solved (gen at first solve) |
|---|---|---|
| Koza 20/20 hits | 6/20 (30 %) | seed 2 (gen 106), 3 (60), 10 (87), 11 (80), 12 (240), 17 (110) |
| Tight SSE < 1e-6 | 2/20 (10 %) | seed 3 (60), seed 17 (110) |
This is consistent with the success rates the PIPE paper reports for Koza’s benchmark with population 100 (the paper sweeps up to population 1000 and hits ≥80 % in that regime).
Hyperparameters (CLI defaults):
| Value | |
|---|---|
| Population per generation | 100 |
| Max generations | 200 (headline) / 300 (sweep) |
| PPT max depth | 6 |
| Initial P(terminal) | 0.6 |
PBIL learning rate lr | 0.2 |
Base target P_T | 0.8 |
| Elite update probability | 0.2 |
Per-program mutation P_M | 0.4 |
Mutation magnitude mr | 0.4 |
| Fitness target | 1 − 1e-6 (SSE < 1e-6) |
| Fitness cases | 20, x ∈ linspace(−1, 1, 20) |
| Hit threshold | |err| < 0.01 (Koza) |
Visualizations
| File | Caption |
|---|---|
pipe_symbolic_regression.gif | Elite curve sliding onto the target across generations 0..60. Early frames: nearly-flat constant predictions. Mid: a shallow even-degree shape (the elite has captured x^2-like terms). Final: indistinguishable overlay of the black target curve. |
viz/fitness_curve.png | Best-of-generation (grey) and elite (blue) 1/(1+SSE). Step structure of the elite line corresponds to discovery moments where a new sampled program improves on the historical best. |
viz/sse_curve.png | Same data, log scale. Elite drops from O(1) at gen 0 to ≈ 1e-30 at gen 60 — twenty-six decades of error reduction. |
viz/hits_curve.png | Koza-hits over generations. The signature is a step from 0–2 hits to 20 in a single generation: the elite either represents the polynomial or it doesn’t. |
viz/fit_curve_overlay.png | Target curve (black) overlaid with elite predictions at four checkpoints (early / 1× / 2× / final). Visualises the symbolic-search analog of “loss decreasing”: each elite is an actual function, and successive elites are increasingly faithful. |
viz/program_size.png | Elite program size and depth over generations. Both grow then plateau when a 15-node, depth-5 representation of the polynomial is found. |
viz/final_fit.png | Final elite vs target on 20 fitness cases. Lines overlap to within plotting precision. |
Deviations from the original
The 1997 paper uses several pieces of GP / PIPE machinery that the v1-numpy posture replaces with smaller equivalents. Each deviation is paired with the reason.
- Default function set is
{+, −, *, /}(paper Table 1 for the Koza benchmark), not the wider{+, −, *, /, sin, cos, exp, log}set that appears in the team-lead guidance. The original Salustowicz & Schmidhuber paper uses the Koza-1992 instruction set for this exact target. The wider set is available behind--funcs full. With the wider set the same hyperparameters reach SSE ≈ 7e-3 / fit 0.993 in 200 generations on seed 0 but do not reliably cross the SSE < 1e-6 line — search space is larger and hit-density is lower. - 20-point uniform grid
linspace(-1, 1, 20)instead of 20 points drawn uniformly at random in [-1, 1]. The paper draws 20 random points; we use a deterministic uniform grid so the test set is identical across seeds. The reachability of the polynomial is the same; what changes is the random point layout, which is irrelevant to whetherx^4+x^3+x^2+xcan be expressed. - Lazy PPT growth at MAX_DEPTH = 6. The paper grows the PPT lazily to whatever depth the sampled programs need and applies a separate depth penalty in fitness. We hard-cap at depth 6 (a Horner-form representation of the target needs depth 5 — sufficient) and force terminals at the cap. No depth penalty in fitness. Documented here because it changes the failure mode: programs cannot grow into bushier-but-incorrect deep trees, but neither can they ever express forms that genuinely need depth > 6.
- Constant mutation by Gaussian random walk on the PPT node, not the
paper’s “constant-renewal” scheme. Whenever the elite re-uses an
Rterminal at a PPT node, we lock in the elite’s value at that node; otherwise mutation drifts the stored constant byN(0, 0.1²). The paper draws a fresh random constant each timeRis sampled during a generation. Both schemes converge to the constant the problem demands; ours has slightly less variance per generation. P_TARGETschedule matches the paper’sP_T + (1 − P_T) · lr · (eps + Fit_best)/(eps + Fit_elite)but is capped at 0.999 to avoid degenerate distributions; the iterative additive update is itself capped at 50 inner steps (in practice it converges in 5–10).
Open questions / next experiments
- Reach 80 %+ success rate on the wider function set. With
{+,-,*,/,sin,cos,exp,log}and pop=100 we land at fit ≈ 0.993 / SSE ≈ 7e-3 on seed 0 in 300 generations. Larger populations (the paper uses up to 1000 individuals) and longer runs should pull the success rate up, but the v1 ≤ 5 min budget limits how much population we can spare. The interesting question is which schedule pulls hardest on success rate per CPU-second: depth, population, or generations. - Compare against Koza GP’s standard crossover-based search. The PIPE paper’s selling point is “no crossover, matches/exceeds Koza GP”. A crossover-and-tournament implementation in this same numpy scaffold would close the comparison. Not in v1 because it doubles the algorithm budget.
- PPT distribution snapshot animation. The current GIF shows the
elite program over time. A complementary visualisation would be a
heatmap of the root-node
Pover generations, showing entropy collapse from uniform to a single dominant symbol. That picture is the direct analogue of “training loss decreases” for a probabilistic search, and is the picture the paper itself uses (Figs. 4–5). - Apply PIPE to harder targets in the same scaffold. Koza’s
quartic is the easiest of the SR targets. Same code applied to
f(x) = x^6 − 2x^4 + x^2,sin(x)·exp(x), or the bivariatex^2 + y^2— all in the original paper — would map the budget scaling to target complexity. - v2 ByteDMD pass. PIPE samples programs and traverses them evaluating arithmetic ops on 20 floats. The data-movement profile should be cheap relative to backprop on a 200-cell LSTM solving the same regression — that comparison is the v2 question this stub feeds into.