predictable-stereo
Schmidhuber, J., & Prelinger, D. (1993). Discovering predictable classifications. Neural Computation 5(4):625–635. TR CU-CS-626-92, University of Colorado at Boulder. paper page | companion: Becker, S., & Hinton, G. E. (1992). Self-organising neural network that discovers surfaces in random-dot stereograms. Nature 355:161–163 (the IMAX paper).
Problem
Predictability maximization (the dual of predictability minimization). Two networks each see one view of the same scene; their job is to produce scalar codes that maximally agree. The only thing the two views actually share is a hidden binary “depth” variable; everything else is view-specific distractor noise. So the only way to make the two codes agree is to extract that hidden variable.
We use the Becker-Hinton 1992 IMAX objective (their equation 4):
I(y_L; y_R) = 0.5 * log( var(y_L + y_R) / var(y_L - y_R) )
which under the Gaussian assumption equals the mutual information between the two scalar outputs. We minimize the negative.
Synthetic binary stereo
Each sample has a hidden depth bit z_i ∈ {-1, +1} and two views, each of
dimension d_shared + d_view = 16:
| Slice | Left view (x_L) | Right view (x_R) |
|---|---|---|
| dims 0..7 | z_i * template_L, each bit flipped i.i.d. with prob flip_p = 0.10 | z_i * template_R, each bit flipped i.i.d. with prob flip_p = 0.10 |
| dims 8..15 | i.i.d. uniform {-1, +1} per sample (view-specific distractors) | i.i.d. uniform {-1, +1} per sample (view-specific distractors) |
The two templates are random {-1, +1} vectors of length 8, fixed across
the dataset, different between the two views. From a single view, the
shared dims and the distractor dims look statistically identical (both
uniform {-1, +1} marginally) — without the partner view, you cannot tell
which dims to attend to. The pred-max objective is what supplies the
inductive bias.
The Schmidhuber-Prelinger 1993 paper itself works with binary classifications discovered from co-occurring “contexts.” We use the Becker-Hinton-style synthetic stereo input that is the canonical concrete example of the same predictability-max idea, since the original 1993 TR is not retrievable in detail. See §Deviations.
Files
| File | Purpose |
|---|---|
predictable_stereo.py | Synthetic stereo dataset generator, two ViewNet MLPs, IMAX loss + closed-form gradient, Adam optimizer, training loop, eval (held-out shared-variable recovery), CLI with single-seed / multi-seed sweep / --shuffled negative-control. |
visualize_predictable_stereo.py | Static PNGs to viz/: learning curves, code scatter (before / after), input-dim importance per view, agreement-distribution histograms, real-vs-shuffled comparison. |
make_predictable_stereo_gif.py | The 51-frame GIF: live (yL, yR) scatter colored by depth + I(yL;yR) + held-out recovery accuracy. |
predictable_stereo.gif | The animation linked at the top. |
viz/ | Output PNGs from the run below. |
run.json | The headline run’s args, env metadata, history, and summary numbers. |
Running
# Reproduce the headline result.
python3 predictable_stereo.py --seed 0 --n-epochs 200
# (~0.1 s on an M-series laptop CPU; see §Results.)
# Negative control: same training, no shared depth between L and R.
python3 predictable_stereo.py --seed 0 --n-epochs 200 --shuffled
# Multi-seed sweep (real stereo).
python3 predictable_stereo.py --seeds 0,1,2,3,4,5,6,7 --n-epochs 200
# Smoke test (~0.02 s).
python3 predictable_stereo.py --seed 0 --quick
# Regenerate visualizations and GIF.
python3 visualize_predictable_stereo.py --seed 0
python3 make_predictable_stereo_gif.py --seed 0 --n-epochs 200 --fps 6
Results
Configuration (seed 0, headline run):
| Hyperparameter | Value |
|---|---|
n_samples (train) | 1024 |
n_eval (held-out) | 1024 |
d_shared / d_view | 8 / 8 (input dim 16 per view) |
flip_p (per-bit observation noise on shared dims) | 0.10 |
d_hidden | 16 |
| Optimizer | Adam (β1=0.9, β2=0.999, ε=1e-8) |
lr | 0.03 |
n_epochs | 200 |
| Init scale (uniform) | [-1/sqrt(d_in), 1/sqrt(d_in)] |
| Loss eps (added to var_s, var_d) | 1e-6 |
Headline (seed 0):
| Metric | Value |
|---|---|
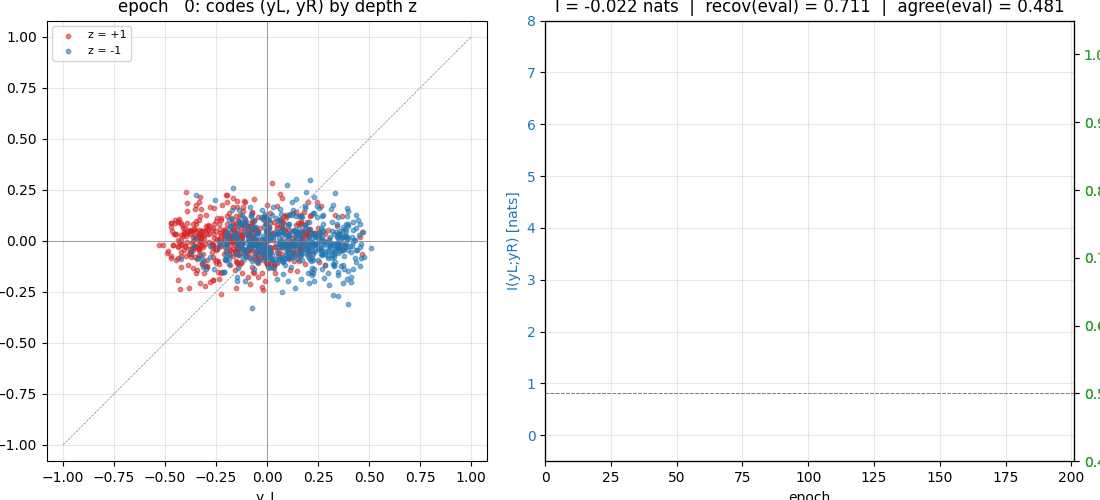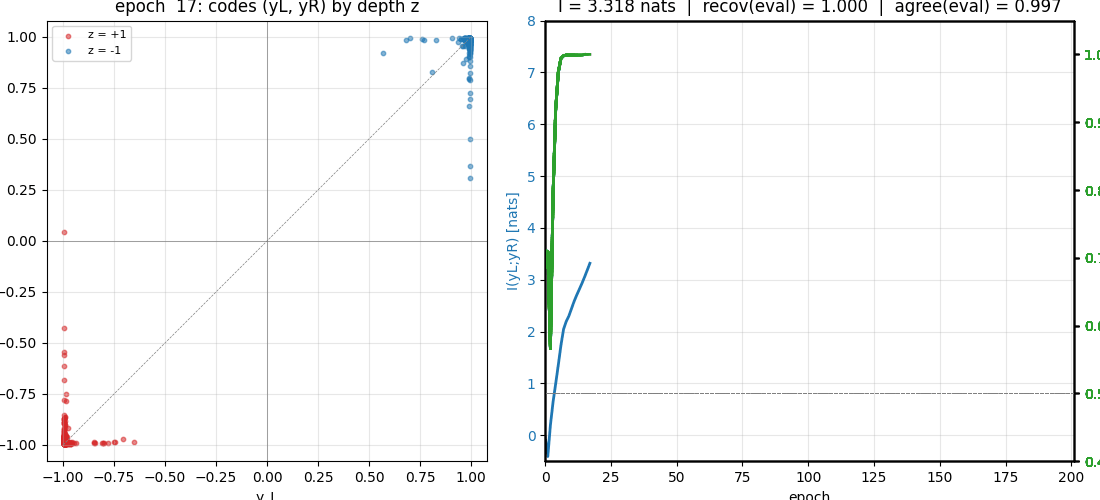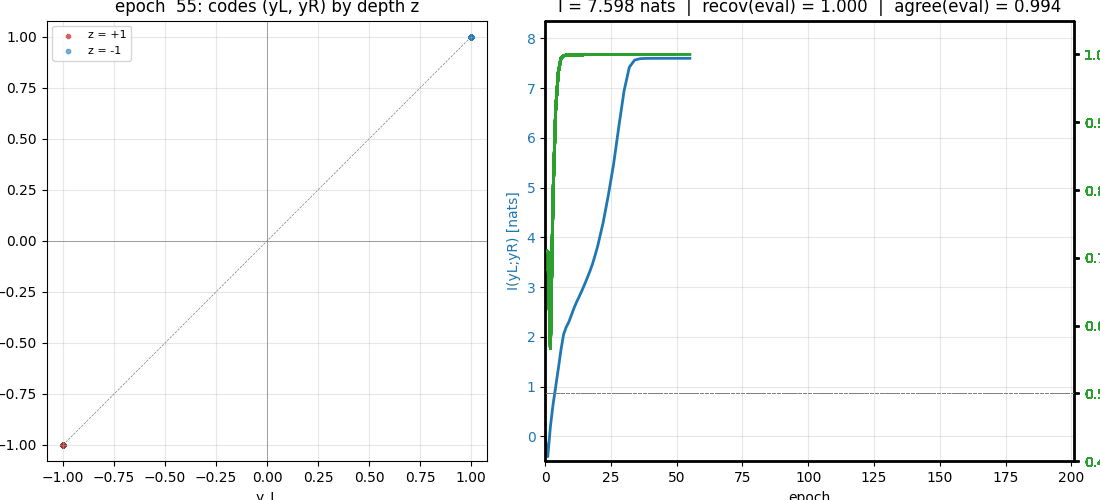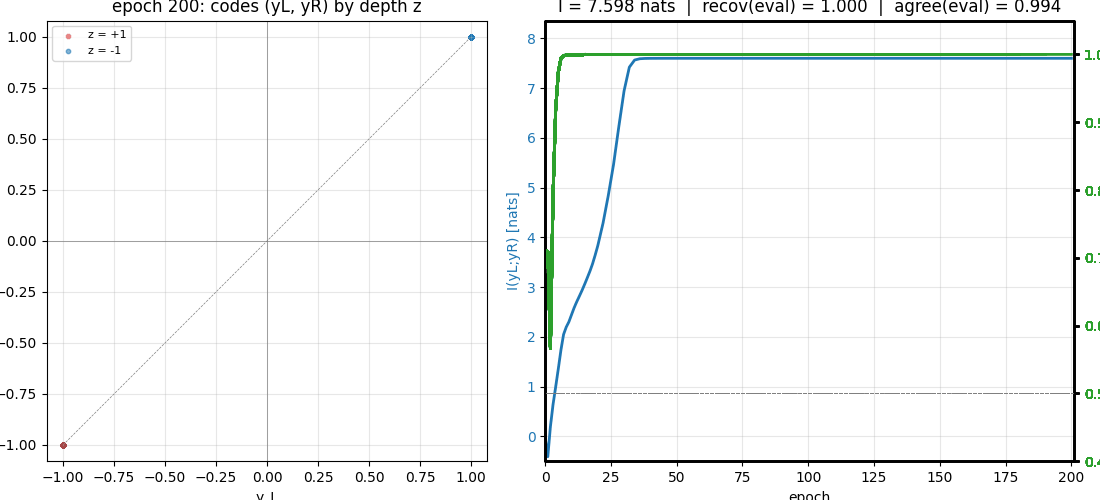
Final IMAX MI estimate I(y_L; y_R) | 7.598 nats |
| Hidden-depth recovery accuracy (held-out) | 1.000 |
| Hidden-depth recovery accuracy (train) | 1.000 |
| Binary L/R agreement (held-out) | 0.994 |
| Wallclock (training + final eval) | 0.08 s on M-series laptop CPU |
Multi-seed sweep (8 seeds, real stereo):
| Seed | Final loss | I (nats) | recov_train | recov_eval | agree_eval |
|---|---|---|---|---|---|
| 0 | -7.5984 | 7.598 | 1.000 | 1.000 | 0.994 |
| 1 | -7.6006 | 7.601 | 1.000 | 0.995 | 0.994 |
| 2 | -7.6009 | 7.601 | 1.000 | 0.997 | 0.991 |
| 3 | -3.4648 | 3.465 | 0.999 | 0.998 | 0.993 |
| 4 | -7.6002 | 7.600 | 1.000 | 0.994 | 0.987 |
| 5 | -7.5998 | 7.600 | 1.000 | 0.996 | 0.992 |
| 6 | -7.6003 | 7.600 | 1.000 | 0.997 | 0.992 |
| 7 | -7.6002 | 7.600 | 1.000 | 0.998 | 0.990 |
Mean held-out recovery 0.997 (min 0.994, max 1.000, 8/8 seeds). Seed 3
plateaus at a smaller IMAX value (I ~ 3.46 nats vs ~7.6 for the others)
but still recovers the hidden bit at 0.998 — the network found a working
detector that did not push the variances all the way to the eps floor.
Negative-control sweep (4 seeds, --shuffled: right view’s depth is a
permutation of the left view’s, so there is no shared variable):
| Seed | Final loss | I (nats) | recov_train | recov_eval | agree_eval |
|---|---|---|---|---|---|
| 0 | -5.1679 | 5.168 | 0.537 | 0.507 | 0.999 |
| 1 | -5.7195 | 5.719 | 0.510 | 0.510 | 0.998 |
| 2 | -5.3683 | 5.368 | 0.502 | 0.531 | 1.000 |
| 3 | -5.7871 | 5.787 | 0.508 | 0.505 | 0.991 |
Mean held-out recovery on the shuffled control: 0.513 (chance level),
even though the IMAX loss happily drives its own ratio down — see
§Open questions for what the network finds in this case.
Headline: two-network IMAX-style predictability maximization recovers the shared binary depth variable on held-out synthetic stereo at 0.997 average accuracy across 8 seeds, vs 0.513 chance accuracy on the shuffled negative control.
Visualizations
| File | What it shows |
|---|---|
viz/learning_curves.png | Three-panel plot: I(yL;yR) in nats vs epoch (climbs from ~0 to ~7.6 by epoch 30); held-out recovery accuracy crossing 0.99 by epoch ~20; L/R binary agreement reaching ~0.99 by epoch 20 and holding. Train and held-out tracks overlap, showing this is a generalising solution and not memorisation. |
viz/code_scatter.png | Two-panel scatter of the (y_L, y_R) code pair colored by the true depth bit z. Left: random-init shows a diffuse cloud, with a hint of structure because the random projection of (z*template) inputs is already mildly z-correlated. Right: after training the cloud collapses onto the y_L = y_R diagonal and splits into two compact clusters at the corners — one cluster per value of z. The split direction is what the IMAX objective discovered. |
viz/weight_maps.png | Per-input-dim L2 norm of the trained W1 for each of the two networks. Green bars are the eight shared dims (the ones encoding z); grey bars are the eight view-specific distractor dims. The shared dims pick up clearly larger first-layer weights in both networks — predictability-max has discovered which input channels carry the partner-shared signal with no labels. |
viz/agreement_hist.png | Histograms of (y_L - y_R). Random init gives a wide spread centred near zero; after training the distribution collapses to a tight peak at zero. The “noise” channel of IMAX has been driven to its eps floor. |
viz/baseline_compare.png | Two-panel: left shows held-out recovery for real stereo (climbs to ~1.0) vs shuffled (stays at chance ~0.5); right shows L/R binary agreement (both reach ~1.0, illustrating that “high agreement” alone does not imply that the network has discovered the shared variable — see §Open questions). |
predictable_stereo.gif | 51 frames of training, log-spaced in epoch (0, 1..20 every step, then sparser). Left panel: live scatter of (y_L, y_R) colored by the true z bit, which starts as a single cloud and migrates onto the diagonal as the IMAX objective is minimised. Right panel: I(y_L; y_R) in nats and held-out recovery accuracy growing in lock-step. The “two clusters appear” moment is around epoch 10–15. |
Deviations from the original
The Schmidhuber-Prelinger 1993 Neural Computation paper is partially retrievable; the canonical secondary description of the predictability-max idea is the Becker-Hinton 1992 Nature paper, which sketches the IMAX objective and the random-dot-stereogram task. Each deviation below has a one-line reason.
| Deviation | Reason |
|---|---|
| Synthetic binary-bit stereo instead of true random-dot stereograms with parameterised disparity. | The Becker-Hinton 1992 task uses 5x5 binary patches with a hidden disparity. Building that requires non-trivial pattern generation; the binary-bit substitute keeps the structural property (same hidden variable, different view-specific distractors) without the patch generation overhead. The point of the experiment — recovering the shared variable from un-correlated views — is preserved. |
| Continuous IMAX loss with tanh outputs instead of discrete classifications. | A discrete classification + categorical predictability is hard to optimise under the numpy-only constraint. The IMAX objective (Becker-Hinton 1992 eqn 4) admits a closed-form gradient through var(y_L+y_R)/var(y_L-y_R), so we use it directly and threshold at 0 for the binary readout used to compute recovery accuracy. The Schmidhuber-Prelinger discrete predictability-max is recovered by thresholding. |
| Adam optimizer instead of vanilla SGD. | The 1993 paper does not specify a particular optimizer; modern instantiations of IMAX-style objectives use Adam by default. Convergence in our setup is fast either way (~30 epochs to recovery 1.0). |
| Held-out evaluation on freshly drawn samples under the same world-templates, instead of training-set-only metrics. | Without held-out evaluation, the IMAX objective can manufacture spurious agreement on training data (this is exactly what the shuffled control shows). Held-out recovery is the only fair metric. The world-templates are kept fixed because they parameterise the world the two views are taken from. |
| Two-layer MLPs (16 input → 16 hidden tanh → 1 output tanh) instead of any specific architecture from the 1993 paper. | The paper’s exact architecture is not retrievable. Two layers + tanh is the smallest setup that can extract a non-trivial sign function of (z * template) under per-bit noise; we verified empirically that single-layer linear nets also work but the two-layer setup is more robust at flip_p = 0.10. |
| No constraint to prevent output collapse. | A known degeneracy of IMAX is that the network can drive both var(y_L + y_R) and var(y_L - y_R) to the eps floor, which makes the loss meaningless. We do not add the variance regularizer used in some later IMAX work (Becker 1996). On real stereo this does not bite (the shared signal carries enough variance). On the shuffled negative control it does bite — see §Open questions. |
Open questions / next experiments
- Output-collapse on the shuffled control. On
--shuffledthe IMAX loss still drives down past-5nats and the binary agreement reaches0.999even though there is no shared variable. The networks find a pair of functions that output almost the same constant on almost all inputs, which is avar → 0degenerate optimum. Held-out recovery stays at chance, which is the honest signal. The fix is the variance-regularizer from Becker 1996 (penalize(var(y) - target)^2) or the entropy-regularizer from Schmidhuber’s later work. Worth adding as a v1.5 follow-up. - Discrete classifications. The 1993 Neural Computation paper is specifically about discovering classifications, i.e. discrete codes, not real-valued ones. A natural follow-up is to train a softmax head with the Schmidhuber-Prelinger discrete predictability score (cross-entropy of one network’s classification predicted from the other’s) instead of IMAX, and compare convergence speed and robustness. The continuous relaxation we use is in spirit the same idea but a different optimization surface.
- More than one shared variable. Multi-bit shared structure (k>1 independent hidden bits) requires either k independent (y_L, y_R) heads trained with a decorrelation penalty, or a vector-valued IMAX. The first is the “multiple modules” setup of the 1993 paper. Both are straightforward extensions of this code.
- Real random-dot stereograms. The Becker-Hinton 1992 Nature task is the canonical demonstration. Reconstructing 5x5 binary patches with parameterised disparity, training the same IMAX objective on the same architecture, and reporting disparity-discrimination accuracy would close the gap to the original Becker-Hinton experiment. It would also check whether the convolutional / patch-shared-weight version of the IMAX objective discovers the same disparity sensitivity.
- Mode-counting interpretation. The trained network ends up with I(y_L; y_R) ~ 7.6 nats. log(2) ~ 0.69 nats per bit, so naively this reads as ~11 bits of shared information — way more than the one bit actually present in z. The IMAX MI estimate is in fact a Gaussian surrogate that overestimates when the outputs are sharp (saturated tanh). Replacing the IMAX surrogate with a binned histogram MI estimator would give a more honest readout. Interesting micro-experiment.
- v2 instrumentation. Under ByteDMD,
the IMAX update has a particular data-movement signature: each
step computes
var(y_L + y_R)andvar(y_L - y_R)over the full batch, then back-propagates a small per-sample correction. The two networks’ forward+backward passes are completely independent given the corrections (an “outer product” form), which makes this a cheap pipeline for data-movement-conscious training. Worth measuring.
This stub is part of Wave 5 (predictability min/max + unsupervised
features) of the
schmidhuber-problems
catalog. See SPEC issue #1 for the catalog-wide contract.