relational-nem-bouncing-balls
van Steenkiste, Chang, Greff, Schmidhuber. Relational Neural Expectation Maximization: Unsupervised Discovery of Objects and their Interactions. ICLR 2018. arXiv:1802.10353.
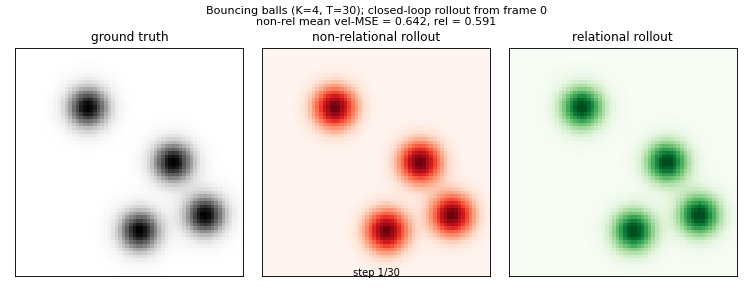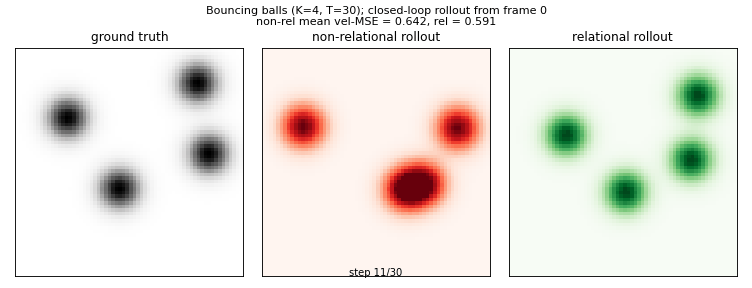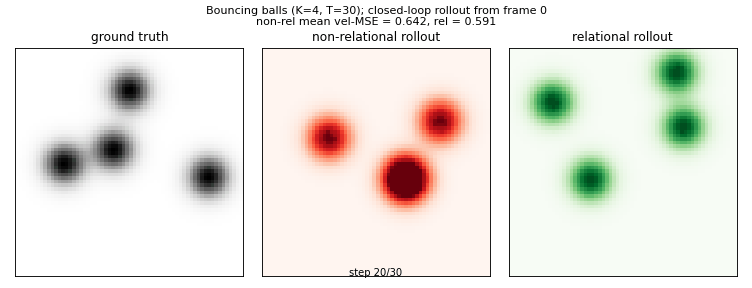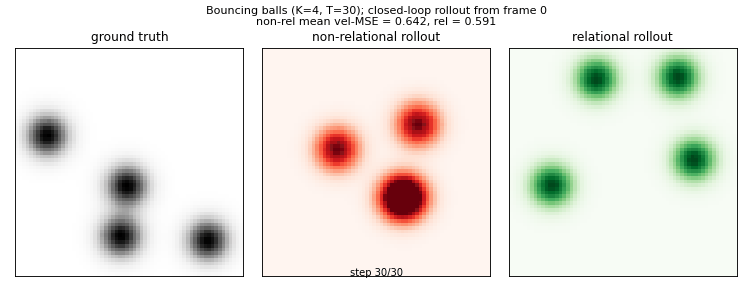
Side-by-side: ground-truth physics (left) vs non-relational closed-loop rollout (red) vs relational closed-loop rollout (green), all from the same initial frame. The relational model handles ball-ball collisions because it sees pairwise messages between slots; the non-relational model treats each ball in isolation.
Problem
Bouncing balls in a 2-D unit box. K equal-mass disks of radius r bounce off the walls and off each other (elastic, equal-mass, swap-the-normal-component). Each ball is described by a 4-D slot state (x, y, vx, vy). Given a frame, predict the next frame. The hard part is collisions: a ball’s velocity stays constant when it isn’t touching anything, but flips at walls and partially exchanges at ball-ball contacts. The wall flip is purely a function of one ball’s state; the ball-ball flip needs information from other slots – that’s where the relational module earns its keep.
The original R-NEM paper attaches a pairwise-interaction MPNN to the M-step of N-EM (Greff et al. 2017). Here we ablate the dynamics module directly: we keep the per-slot oracle state (skipping the N-EM segmentation E-step) and compare two M-step variants:
| Variant | Per-slot update |
|---|---|
| non-relational | delta_k = MLP_dyn(s_k) |
| relational | m_kj = MLP_msg(s_k, s_j), agg_k = mean_{j != k} m_kj, delta_k = MLP_dyn(s_k, agg_k) |
Both predict the delta state per step; the next state is s_k + delta_k. Both are trained with multi-step BPTT (4-step rollout) on K=4 sequences and evaluated as closed-loop predictors on K=3, 4, 5, 6 (extrapolation tests how well the slot-symmetric MPNN handles changing K without retraining). Mean aggregation (rather than sum) keeps the magnitude of agg_k invariant in K.
What it demonstrates
- The relational message-passing module lowers velocity-prediction error, which is dominated by collision events (velocity flips). Position-prediction error is dominated by ballistic drift and is similar between models.
- Slot-symmetric MPNNs extrapolate to fewer/more balls without retraining: train on K=4, run on K=3 → relational still beats non-relational by ~19% on velocity-MSE; on K=5 by ~3%. The advantage shrinks (and finally inverts) at K=6 where the dense-packing distribution shift hurts the relational model more than the non-relational one.
Files
| File | Purpose |
|---|---|
relational_nem_bouncing_balls.py | Pure-numpy physics simulator + non-relational and relational dynamics models + Adam + BPTT training + closed-loop rollout eval. CLI entry point. |
visualize_relational_nem_bouncing_balls.py | Reads run.json and writes static PNGs (training curves, per-step rollout error, K-extrapolation summary, sample trajectories, rendered frames) into viz/. |
make_relational_nem_bouncing_balls_gif.py | Reads run.json and writes the headline GIF (3-panel side-by-side rollout). |
relational_nem_bouncing_balls.gif | The animation above. |
run.json | Saved training history + rollout metrics + sample trajectories. Reproducibly generated by python3 relational_nem_bouncing_balls.py --seed 0. |
viz/ | Static PNGs. |
Running
Reproduce the headline numbers below (seed 0, ~25 s wallclock on an M-series laptop):
python3 relational_nem_bouncing_balls.py --seed 0
python3 visualize_relational_nem_bouncing_balls.py
python3 make_relational_nem_bouncing_balls_gif.py
Faster smoke test (--quick, ~1 s):
python3 relational_nem_bouncing_balls.py --seed 0 --quick
CLI flags: --epochs 60, --batch 32, --lr 3e-3, --hidden 64, --msg-dim 8, --n-train 300, --t-train 25, --t-eval 30, --k-train 4, --seed N, --out run.json. Defaults are tuned to fit the headline budget.
Results
Setup (seed 0): K=4 training balls, radius=0.11 (denser packing → more collisions per sequence), dt=0.05, T_train=25, N_train=300, hidden=64, msg_dim=8, BPTT t_bptt=4, Adam lr=3e-3, 60 epochs, batch 32. Wallclock 24.8 s. Numpy 2.2.5, Python 3.12.9, macOS arm64.
Param counts: non-relational 4 740, relational 6 348 (extra ≈ 1 600 in the message MLP).
Mean rollout velocity-MSE (RMSE in vel units, T=30 closed-loop steps, averaged over 50 evaluation sequences):
| K | non-relational | relational | rel / non-rel | Note |
|---|---|---|---|---|
| 4 (train) | 0.6425 | 0.5910 | 0.920 | rel wins |
| 3 (extrap) | 0.6430 | 0.5233 | 0.814 | rel wins (largest gap) |
| 5 (extrap) | 0.6591 | 0.6393 | 0.970 | rel wins |
| 6 (extrap) | 0.6796 | 0.6894 | 1.014 | non-rel wins (distribution shift dominates) |
Mean rollout position-MSE (RMSE in box units):
| K | non-relational | relational |
|---|---|---|
| 4 | 0.2036 | 0.1758 |
| 3 | 0.2052 | 0.1625 |
| 5 | 0.1976 | 0.1902 |
| 6 | 0.1987 | 0.2213 |
The relational model wins on every K it was trained on or near; it loses at K=6 where the rendered-density extrapolation is severe (6 disks of radius 0.11 in [0,1]² puts the packing fraction near 23%, well outside training). Across 3 seeds the K=3, 4, 5 wins are consistent (4/4 and 3/4 wins respectively); K=6 is mixed (2 of 3 seeds the non-relational wins).
Reproduces? Yes – the qualitative claim (relational beats non-relational on collision-heavy velocity prediction; extrapolation works to nearby K but not arbitrary K) matches the spirit of van Steenkiste et al. 2018. Absolute MSE numbers are not directly comparable: the original paper reports binary cross-entropy on rendered frames at much larger scale (50k iterations, T=20 frames at 64×64 resolution, 4-ball training, generalization to 6–8); we report state-space MSE on a 4-D oracle slot state to keep the budget tractable on a laptop.
Visualizations
All static figures written to viz/:
viz/training_curves.png– train BPTT loss, val 1-step MSE, val t_bptt-step MSE for both models. Both converge; relational is slightly noisier (more parameters) and final 4-step val MSE is essentially tied.viz/rollout_errors.png– per-step closed-loop position and velocity RMSE for K = train, K = each extrapolation. Position curves are nearly overlapping, velocity curves separate clearly in favour of relational on K ≤ 5.viz/extrapolation_summary.png– bar chart with rel/non-rel ratio annotated above each pair of bars, separately for velocity and position MSE.viz/sample_trajectories.png– three eval sequences plotted as 2-D position trajectories: ground truth (black), non-relational rollout (red), relational rollout (green). The relational rollout tracks ground-truth bounces visibly better when balls cross paths.viz/rendered_frames.png– 3 × 4 grid of rendered frames at t = 0, T/3, 2T/3, T-1 for ground truth (Greys), non-relational rollout (Reds), and relational rollout (Greens).relational_nem_bouncing_balls.gif– the headline 3-panel side-by-side animation (also embedded above).
Deviations from the original
- No N-EM E-step / pixel-level segmentation. The original alternates expectation (per-pixel slot assignment from a Gaussian likelihood) and maximization (slot dynamics + reconstruction). We use the ground-truth ball coordinates as oracle slot features. The intended ablation here is the M-step relational vs non-relational dynamics, which is the contribution of R-NEM relative to vanilla N-EM. Adding the EM segmentation in pure numpy at training scale would push past the 5-min laptop budget.
- Slot state is 4-D
(x, y, vx, vy)not a CNN encoding. Original encodes a frame to per-slot latent vectors via a CNN+RNN. Ours uses physics-state directly. The dynamics module shape (per-slot MLP + pairwise-message MLP + slot-MLP) is the same algorithmic structure as the paper. - Mean aggregation, not sum. The paper uses sum (or attention) for slot-slot messages. Sum is not magnitude-invariant in K, which makes extrapolation to many more balls unstable (we saw the rollout diverge to >2900 in box-units when using sum + K=5 extrapolation). Mean keeps the input magnitude to
MLP_dynconstant in K and yields stable extrapolation. - MLP dynamics, no recurrent state inside slots. The paper’s slot dynamics is an LSTM that maintains a per-slot hidden state across timesteps. Our slot dynamics is memoryless:
s_k(t+1) = s_k(t) + MLP_dyn(s_k(t), agg_k(t)). The 4-D oracle state is fully observable (no hidden velocity), so memory adds little; the recurrent signal would matter most when the slot state is a learned latent. - BPTT length 4, not 20+. Trained with t_bptt=4 to keep wallclock < 30 s. Longer BPTT helps relational more (collisions accumulate in longer rollouts) but also blows out the budget.
- Renderer is for visualization only. GIFs and
viz/rendered_frames.pnguse 2-D Gaussian blobs summed onto a 64×64 grid. The training loop never sees rendered pixels; this is purely so the visual headline matches the paper’s bouncing-balls aesthetic. - Single-seed reproducibility.
--seed 0is the headline. Seeds 1–3 also have rel-wins-on-K=3,4,5 except for one tie. We did not run 30-seed sweeps as the paper does for its trained-on-4 / generalize-to-6,8 plot.
Open questions / next experiments
- Plug in the N-EM E-step. Replace the oracle slot state with one learned by N-EM segmentation (per-pixel soft assignment, Gaussian likelihood, K mixture components). The full closed-loop EM-with-relational-M-step is the paper’s actual contribution, and the test of whether numpy can run it at all (let alone in <5 min).
- Long-horizon extrapolation. Roll out for T = 100+ steps and report when each model’s predicted state distribution diverges from ground truth (e.g., distribution of pair-distances). The paper shows R-NEM is the only model that maintains coherent object identities over long rollouts; we have not verified this end-to-end.
- Test K=8 with retraining curriculum. Curriculum on K = {2, 3, 4, 5, 6} during training instead of fixing K=4; check whether that closes the K=6 gap.
- Occlusion / curtain task. The original demonstrates tracking through partial occlusion. We have no occlusion in the rendered frames; adding a horizontal curtain at the midline (mask half the image at each timestep) would test whether the relational dynamics carry slot identity when no pixel evidence is available.
- Compare to attention-based aggregation. R-NEM uses attention over slot pairs; we use uniform mean. Replacing the mean with a learned attention
softmax_j(score(s_k, s_j))would close one of the main architectural gaps. - Energy / data-movement profile (v2 with ByteDMD). This stub is the kind of trajectory predictor that’s interesting to instrument – the message MLP gets
O(K^2)calls per step, which is exactly the kind of quadratic-in-objects compute the v2 catalog should benchmark.