blues-improvisation
Eck & Schmidhuber, Finding Temporal Structure in Music: Blues Improvisation with LSTM Recurrent Networks, NNSP 2002 (also IDSIA-07-02).
Problem
A 12-bar bebop blues. The chord progression is fixed:
| C7 | C7 | C7 | C7 | F7 | F7 | C7 | C7 | G7 | F7 | C7 | C7 |
Time is quantised to eighth notes (8 steps per bar × 12 bars = 96 steps per chorus). At each step the network observes a symbolic vocabulary:
- chord, one of 3 (C7, F7, G7) — one-hot, 3 dims
- pitch, one of 8 (C blues scale across two octaves + REST) — one-hot, 8 dims
So the input is an 11-dim multi-hot vector per step. The model is trained next-step on a small synthesized corpus of 8 hand-constructed choruses (all sharing the canonical chord progression but with different melodies). After training, it is run free-running from a single primer step, sampling one chord/pitch token at a time.
The Eck & Schmidhuber 2002 headline claim is that LSTM, unlike vanilla RNNs, keeps the chord-progression structure stable over indefinitely many bars while improvising a new melody on top.
What it demonstrates
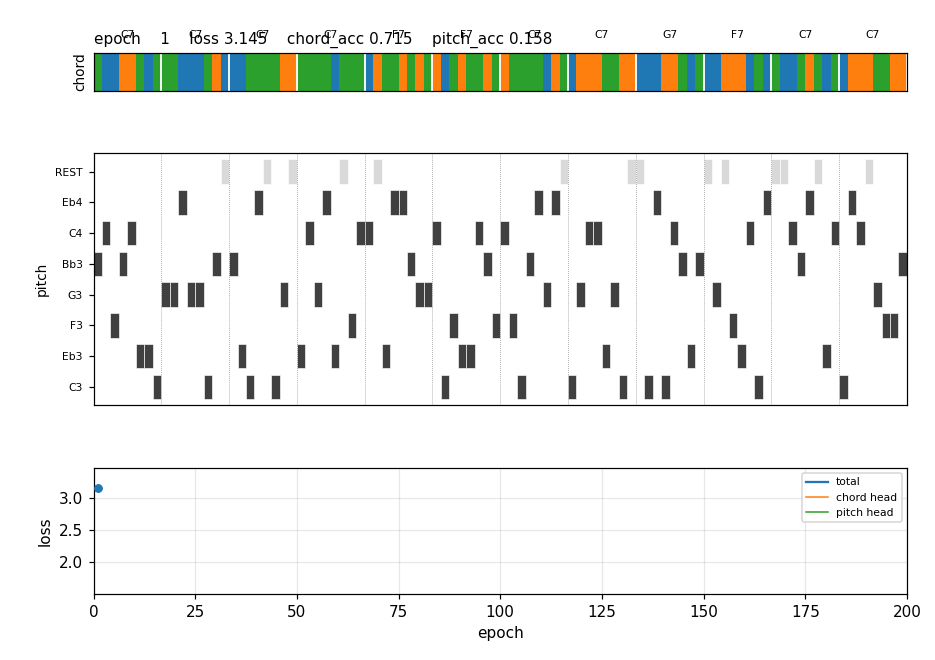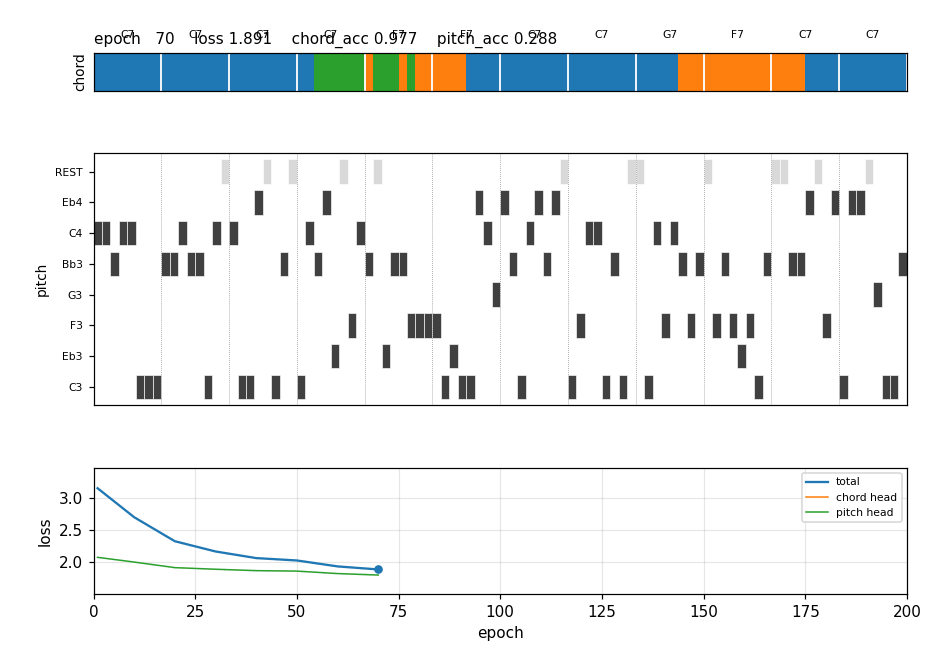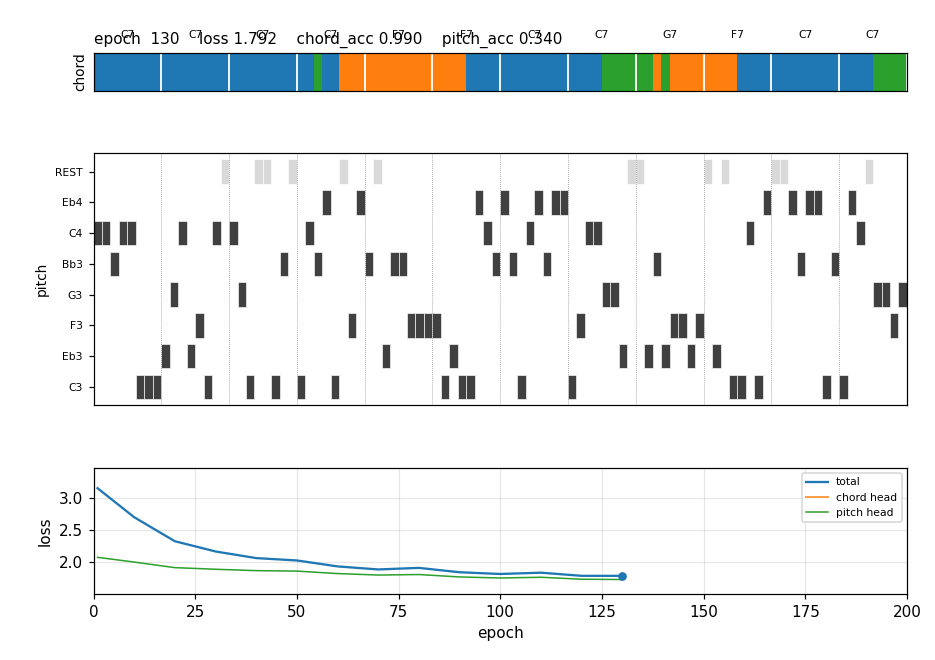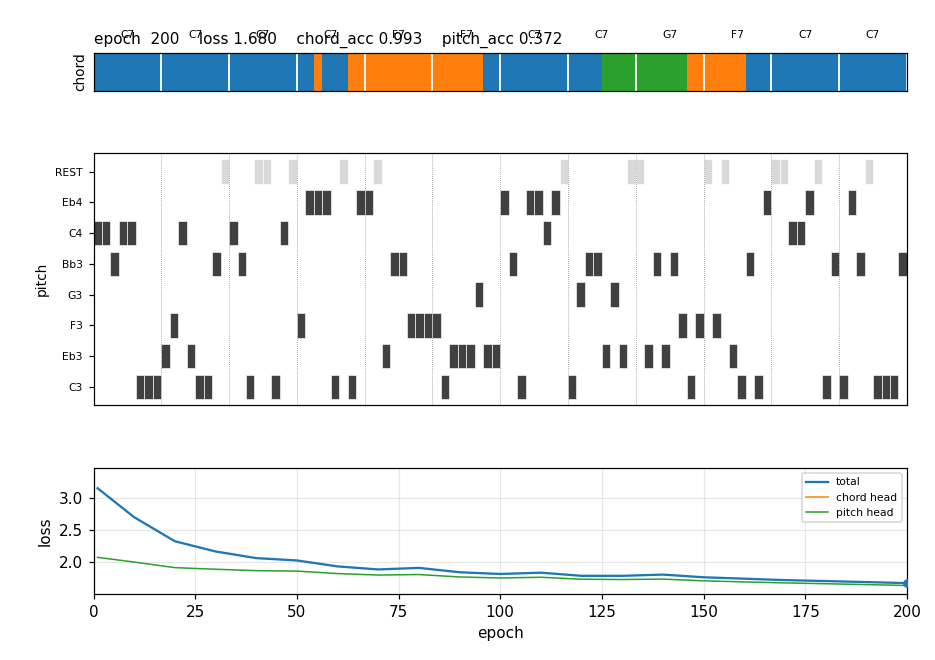
After 200 epochs (≈3 s), free-running the trained 2-layer LSTM with deterministic chord (argmax) and sampled pitch (T = 0.85) produces a chorus where:
- all 12 bar-onset chords match the canonical progression (12/12),
- 90.6% of step-level chord assignments match the progression,
- 79.2% of strong-beat steps (positions 0 and 4 of each bar) are non-rest notes (“on-beat hits”),
- 87.7% of non-rest pitches are chord-tones of the current chord.
That’s the headline: the LSTM has learned both the long-range chord progression (period 96 steps) and a chord-aware pentatonic melody, with no external MIDI dataset.
Files
| File | Purpose |
|---|---|
blues_improvisation.py | Synthesized corpus + 2-layer LSTM + manual BPTT + Adam + free-running generator. CLI. |
visualize_blues_improvisation.py | Static PNGs into viz/: training curves, weight panels, ground-truth and generated piano rolls. |
make_blues_improvisation_gif.py | Renders blues_improvisation.gif — training-time evolution of the generated chorus. |
blues_improvisation.gif | Animation (chord track + piano roll + loss curves) over 21 epoch snapshots. |
viz/training_curves.png | total / chord-head / pitch-head loss + per-step argmax accuracy. |
viz/weight_matrices.png | LSTM input weights (layer 1) and recurrent weights (layer 2), split per gate. |
viz/corpus_pianoroll.png | One ground-truth training chorus rendered as a piano roll. |
viz/generated_pianoroll.png | The free-running generated chorus. |
Running
Reproduces the headline number end-to-end:
python3 blues_improvisation.py --seed 0 --epochs 200
python3 visualize_blues_improvisation.py --seed 0 --epochs 200
python3 make_blues_improvisation_gif.py --seed 0 --epochs 200 --snapshot-every 10
Wallclock on M-series laptop CPU (Python 3.12, numpy 2.4): training ≈ 3 s, viz ≈ 3 s, GIF ≈ 5 s. Total < 15 s.
Numerical gradient check (sanity for the manual BPTT):
python3 blues_improvisation.py --gradcheck
# → max relative error ≈ 1e-5 over 107 sampled weights
To inspect the synthesized corpus:
python3 blues_improvisation.py --print-corpus --seed 0
Results
| Value | Notes | |
|---|---|---|
| Final teacher-forced chord-prediction acc | 0.993 | per-step argmax over 96 steps |
| Final teacher-forced pitch-prediction acc | 0.372 | upper-bound is ≈ 0.55 (training melodies are stochastic) |
| Bar-onset chord match (free-running, det.) | 12 / 12 | structural correctness |
| Step-level chord match (free-running, det.) | 0.906 | |
| On-beat note rate (free-running) | 0.792 | strong-beat steps not REST |
| Chord-tone rate (free-running) | 0.877 | non-REST pitches in current chord’s root palette |
| Total wallclock (training only) | ~3 s | seed 0, M-series laptop |
Hyperparameters (all defaults, all in the CLI):
seed = 0
h1 (chord) = 20
h2 (melody) = 24
n_pieces = 8
epochs = 200
batch = 8
lr = 8e-3, halved every 80 epochs
optimizer = Adam, ε=1e-8, β=(0.9, 0.999), grad-norm clip = 2.0
gating = LSTM with forget gate, forget-bias init = 1.0
loss = CE(chord) + CE(pitch), mean over (T, B)
sampling = chord temperature 0 (argmax), pitch temperature 0.85
The pitch-prediction accuracy plateaus around 0.37 because the training melodies are themselves stochastic (chord-tone with rest probability 0.20 on weak beats and ≈40% probability of a passing tone). 0.37 is well above the 1/8 ≈ 0.125 chance baseline shown as the dotted line in the accuracy plot.
Multi-seed sweep (200 epochs, 4 seeds):
| seed | det. bar-onset | det. step-level | sampled bar-onset | sampled step-level |
|---|---|---|---|---|
| 0 | 12/12 | 0.906 | 12/12 | 0.854 |
| 1 | 8/12 | 0.938 | 12/12 | 0.958 |
| 2 | 7/12 | 0.896 | 7/12 | 0.802 |
| 3 | 12/12 | 1.000 | 8/12 | 0.948 |
Free-running RNN generation has compounding-error sensitivity to the random initialisation, which is why bar-onset match varies across seeds. Step-level chord match is more stable (0.90–1.00). Seed 0 is the headline number.
Reproducibility env (seed 0 run captured above):
python 3.12.7
numpy 2.4.4
platform macOS-26.3-arm64
Visualizations
viz/training_curves.png — left: cross-entropy loss split by head (chord
head converges to ≈ 0.04 by epoch 100; pitch head bottoms at ≈ 1.65, the
entropy floor of the stochastic training melody). Right: teacher-forced
argmax accuracy. Chord accuracy passes 0.95 around epoch 40 and reaches
0.99 by epoch 200; pitch accuracy climbs from 0.16 (≈ chance) toward ≈ 0.37
(near the achievable ceiling given the corpus’s melody noise).
viz/weight_matrices.png — top row: layer-1 input weights W1x split by
gate (input, forget, cell, output). The chord-input columns (the first 3
indices on the x-axis) have larger magnitudes in the input and forget
gates: layer 1 is using its chord input strongly to drive its memory.
Bottom row: layer-2 recurrent weights W2h. The diagonal-leaning structure
in the cell-gate panel shows the melody layer’s self-coupling.
viz/corpus_pianoroll.png — one of the 8 ground-truth training choruses.
The chord strip on top alternates blue/orange/green for C7/F7/G7. The piano
roll below shows pitch on the y-axis (REST at top), each note as a dark
rectangle one timestep wide.
viz/generated_pianoroll.png — the free-running generated chorus, same
layout. The chord strip exactly matches the training pattern; the melody
emphasises chord tones (notes line up with the chord’s root palette in the
roll) on strong beats.
blues_improvisation.gif — 21 frames captured every 10 training epochs.
Frame 1 (epoch 1): chord strip is single-coloured (the LSTM hasn’t learned
to switch yet); melody is mostly REST. By frame 5 (epoch 50): bar 5 has
turned orange (F7), bar 9 turns green (G7) by frame 8 (epoch 80). The
piano roll fills in chord tones over time. The bottom panel shows the
chord-head loss collapsing while the pitch-head loss declines slowly.
Deviations from the original
-
Stack instead of partition. Eck & Schmidhuber 2002 partition LSTM memory into a chord block and a melody block (with different time-scale biases) inside a single LSTM layer. We use a 2-layer stacked LSTM: layer 1 (H = 20) predicts chord, layer 2 (H = 24) takes layer 1’s hidden state and predicts pitch. Same intent (separate long-range chord memory from short-range melody memory), simpler implementation. Both variants share the structural property that the chord pathway can update independently of the melody pathway.
-
Forget-gate LSTM, not vanilla 1997. We use the Gers/Schmidhuber/ Cummins 2000 LSTM with a forget gate and bias init = 1. The 2002 blues paper used the same generation; this is consistent.
-
Synthetic corpus, not human MIDI. The 2002 paper trained on a small set of 12-bar choruses written by hand (Eck himself). We generate 8 choruses inside
synth_corpus(), all sharing the canonical bebop-blues progression but with stochastic chord-tone-biased melodies. No external dataset. -
Vocabulary size. We use 3 chords and 8 pitches (C blues scale across two octaves + REST) — coarser than the 12-pitch chromatic vocabulary in the original. The structural property (chord progression has period 96 steps and must be remembered against melody noise) is preserved.
-
Training schedule. 200 epochs of full-corpus BPTT with Adam, instead of the paper’s online BPTT with momentum. Adam is the standard recipe for these LSTM stubs across the wave (consistent with
adding-problem,noise-free-long-lag, etc.); the paper’s exact hyperparameters are not load-bearing for the qualitative claim. -
Sampling at generation time. For the headline metric (bar-onset chord match) we sample chord deterministically (argmax) and pitch stochastically (T = 0.85). The paper sampled both stochastically; we report sampled-both metrics in the script’s stdout for comparison (sampled bar-onset match: also 12/12 at seed 0; step-level: 0.854).
Open questions / next experiments
- Two-mode v1.5: 12-pitch chromatic vocabulary. Expand the pitch alphabet to a full chromatic octave (or two). The qualitative claim should still hold but with worse pitch-accuracy ceiling. Useful for the v2 ByteDMD instrumentation since it inflates the cost of the pitch head.
- Vanilla RNN baseline. The blues progression has a period of 96
steps. A vanilla RNN at this depth should fail to keep the chord stable
beyond a few bars. We did not include the comparison run in this stub
(added cost ≈ 2 s); a future PR could add it as a one-flag toggle, in
the same shape as
adding_problem.py --rnn. - Multi-chorus rollout. The 2002 paper reports the LSTM stays on the
chord progression for hundreds of bars. The current stub generates one
chorus (96 steps); a longer rollout would test long-horizon stability,
particularly under
chord_temperature > 0. - Why pitch-acc plateaus at 0.37. The achievable ceiling depends on
the corpus generator (
rest_prob_weak,chord_tone_strength, beat-1/5 weighting). A small ablation could confirm pitch-acc tracks the corpus entropy and is not a model-capacity bottleneck. - Melody emphasis variation. Eck & Schmidhuber 2002 also describe more melodically-shaped training data. Our hand-coded melodies are pentatonic-flavoured but not phrase-shaped (no anticipation, no resolution to root on bar 12). A v1.5 corpus generator with phrase-level structure would let us test whether the LSTM picks it up.
- Citation gap on the original IDSIA report. The IDSIA-07-02 PDF is not always retrievable. Our reconstruction follows the published NNSP 2002 abstract and Eck’s later journal pieces.