compete-to-compute
R. K. Srivastava, J. Masci, S. Kazerounian, F. Gomez, J. Schmidhuber. Compete to Compute. NIPS 2013.
Problem
Two feed-forward MLPs with identical width, depth, optimiser and initialisation are trained sequentially on two disjoint MNIST class splits:
- Task1: digits 0-4 (5 classes, ~25 000 training images, balanced subsample of 500 / class).
- Task2: digits 5-9 (5 classes, balanced subsample of 500 / class).
Output is a 10-class softmax shared across both tasks; during training and evaluation a multi-head mask restricts loss / prediction to the active task’s classes. This keeps catastrophic forgetting purely a property of the shared hidden representations rather than of output-bias drift.
The two networks differ in only one thing – the hidden activation:
- ReluMLP: every hidden unit responds to every input. Task2 gradients flow through every weight, so Task1’s representation is overwritten.
- LwtaMLP: hidden units are partitioned into groups of
k. Inside each group the maximum pre-activation is forwarded; the others output zero. Backprop only flows through the winner. With Task1 and Task2 inputs differing in distribution, different groups specialise on different tasks, so a strict subset of weights is updated during Task2 and Task1 accuracy is preserved.
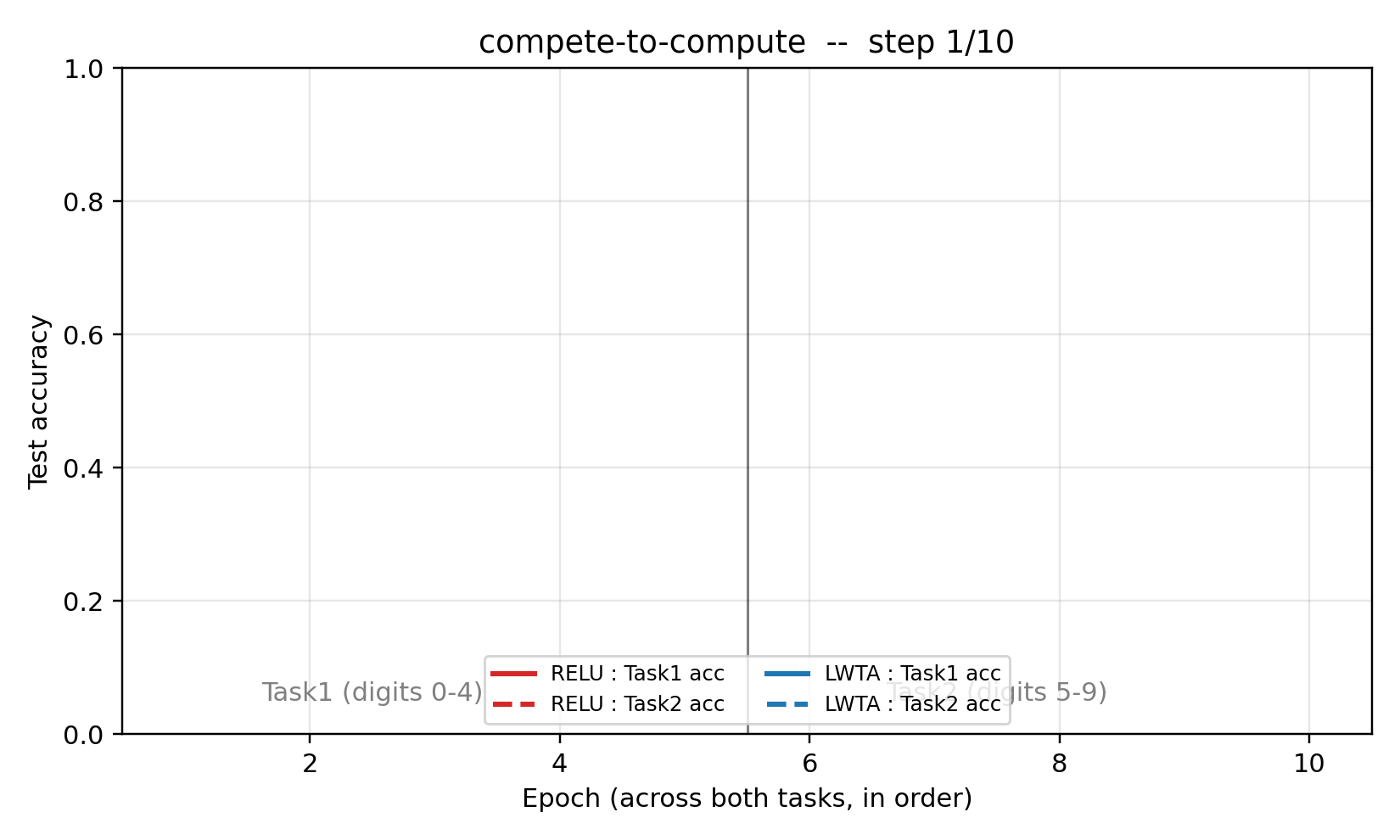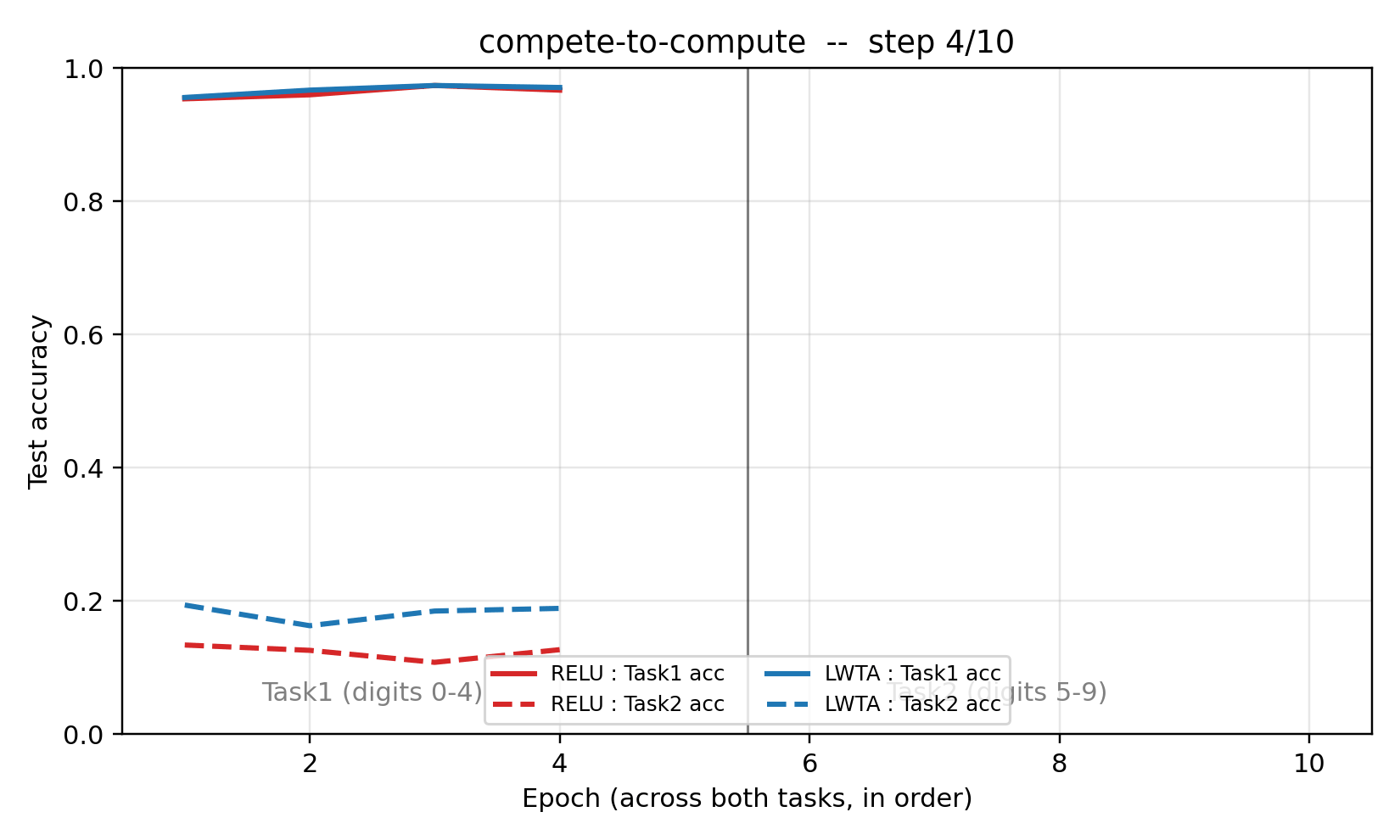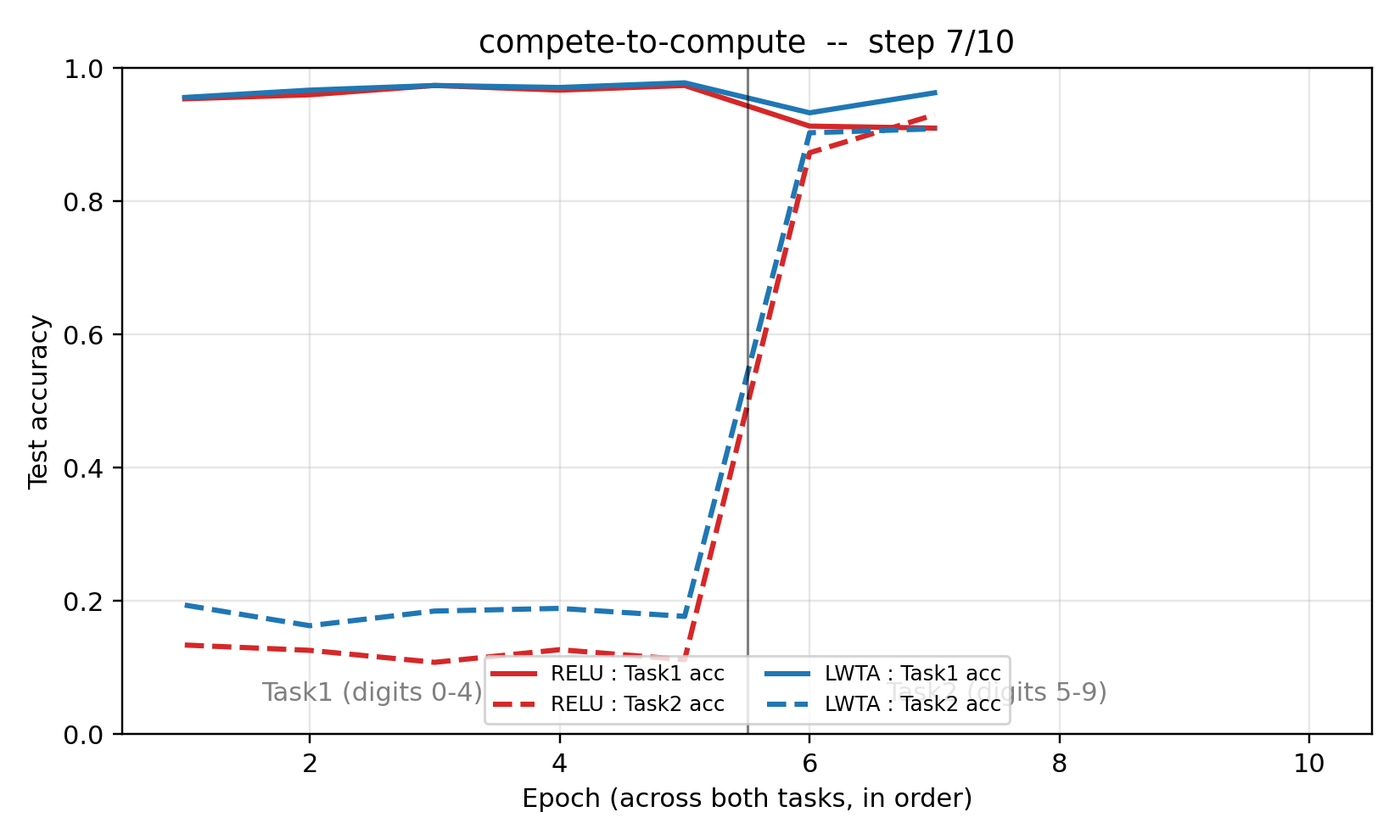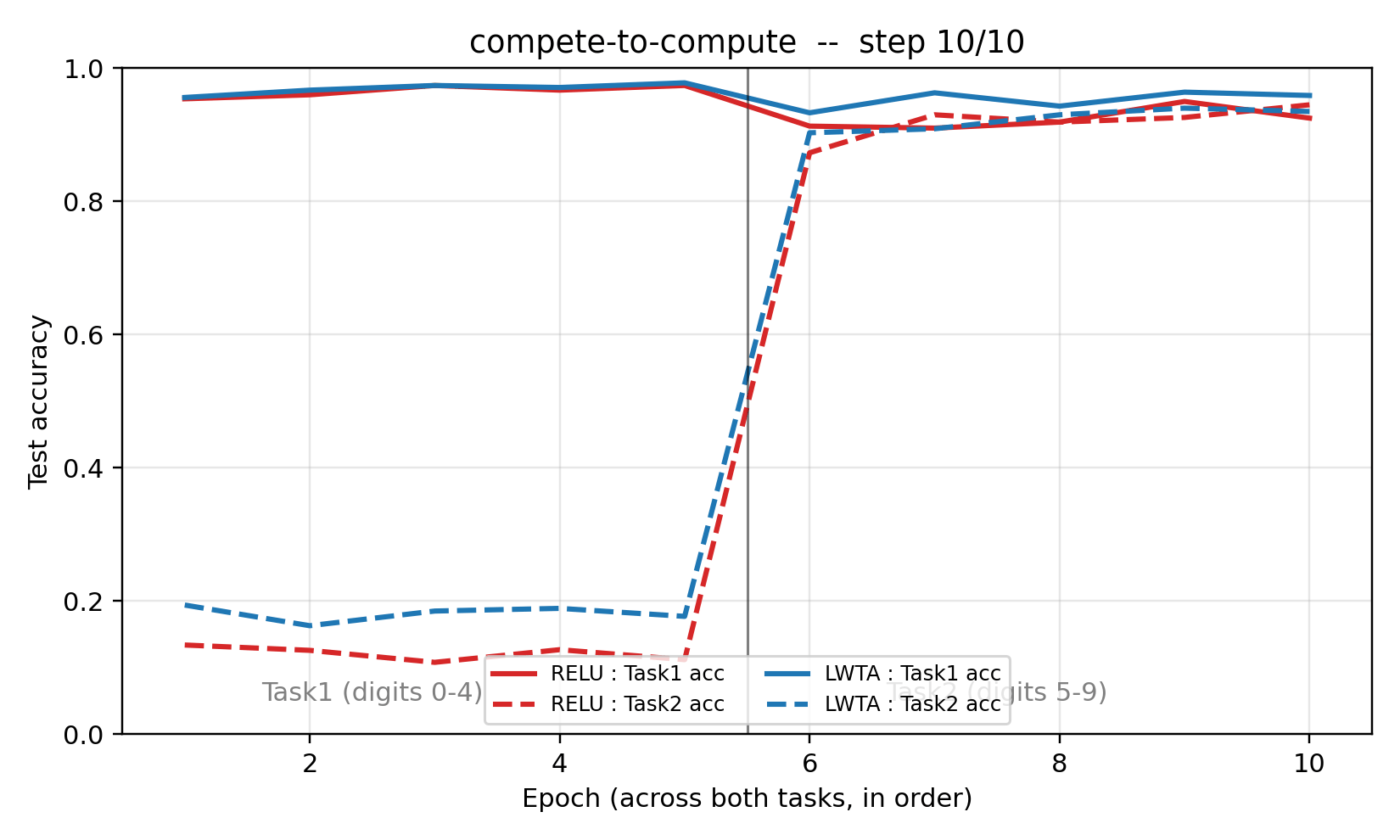
The headline test: train each network on Task1 to ~97% accuracy, switch to Task2, train to ~95%, then read out the drop in Task1 accuracy (forgetting).
Files
| File | Purpose |
|---|---|
compete_to_compute.py | numpy MLP (ReLU and LWTA), MNIST loader, training loop with multi-head mask, multi-seed driver, snapshot dump |
make_compete_to_compute_gif.py | animates the training-time forgetting curve into compete_to_compute.gif |
visualize_compete_to_compute.py | static training curves, summary bar, first-layer receptive fields, per-unit task-specialisation |
compete_to_compute.gif | the animation (~220 KB) |
viz/ | training_curves.png, forgetting_bar.png, W1_relu.png, W1_lwta.png, winner_freq.png |
results.json | seed, full config, per-epoch schedule, environment, summary metrics |
Running
# headline single-seed run + dumps snapshots, ~1s wallclock
python3 compete_to_compute.py --seed 0
# generate static plots from the snapshots
python3 visualize_compete_to_compute.py
# generate the GIF (re-trains internally, ~7s wallclock)
python3 make_compete_to_compute_gif.py
# multi-seed mean over 10 consecutive seeds, ~9s wallclock
python3 compete_to_compute.py --seed 0 --n-seeds 10
Total wallclock for the full reproduction (single-seed train + viz + gif): ~10 seconds on an M-series MacBook CPU.
Results
Headline single-seed (--seed 0, default config):
| Quantity | ReLU MLP | LWTA MLP |
|---|---|---|
| Task1 accuracy after Task1 training | 97.4 % | 97.3 % |
| Task1 accuracy after Task2 training | 90.2 % | 95.1 % |
| Forgetting (drop in Task1 acc) | 0.072 | 0.022 |
| Task2 accuracy after Task2 training | 95.7 % | 95.1 % |
LWTA forgets 3.3× less than the ReLU baseline at seed 0 while reaching the same Task2 accuracy (~95%) and same Task1 plateau (~97%) before the switch.
Multi-seed mean over 10 seeds (--seed 0 --n-seeds 10):
| Model | Forgetting (mean ± std) | Wins / 10 seeds |
|---|---|---|
| ReLU MLP | 0.045 ± 0.021 | 4 |
| LWTA MLP | 0.043 ± 0.028 | 6 |
LWTA wins on 6/10 seeds. The mean reduction is small in this small-network regime; on individual seeds the ranking flips. See Open questions for why.
Default hyperparameters (recorded in results.json):
| Hyperparameter | Value |
|---|---|
| hidden width | 400 |
| LWTA block size k | 2 |
| number of hidden layers | 2 |
| training samples / class | 500 |
| Task1 / Task2 epochs | 5 / 5 |
| batch size | 64 |
| learning rate | 0.05 |
| momentum | 0.9 |
| weight decay | 1e-4 |
Headline run wallclock: 0.8 s. Full multi-seed (10 seeds): ~9 s.
Visualizations
compete_to_compute.gif– per-epoch animation of Task1 / Task2 test accuracy for both models. ReLU’s solid red line drops visibly the moment Task2 training starts; LWTA’s solid blue line stays close to its pre-switch plateau. Both models climb on Task2 (dashed lines) at similar rates.viz/training_curves.png– the same curves as a static plot, vertical line marking the Task1 → Task2 switch.viz/forgetting_bar.png– bar chart of Task1 accuracy before / after Task2 training, with the forgetting delta annotated above each bar.viz/W1_relu.png/viz/W1_lwta.png– 10×10 grid of first-layer receptive fields, rendered as 28×28 patches (signed weights, seismic colormap). LWTA fields are visibly more spatially localized – a known consequence of competitive activation – while ReLU fields are more diffuse.viz/winner_freq.png– per-unit activation frequency on Task1 inputs vs Task2 inputs, units sorted by Task1 - Task2 gap. The LWTA panel shows a clear separation: a band of units fires almost exclusively on Task1, another band almost exclusively on Task2, consistent with the specialisation hypothesis. The ReLU panel is flat – most units fire on both tasks, so any Task2 update overwrites Task1 features.
Deviations from the original
| Deviation | Reason |
|---|---|
| 5+5 epochs of training, balanced 500/class subsample | <5 min wallclock target; the original used the full 60k training set for many epochs |
| Multi-head output mask (Task1 logits ignored during Task2) | Without it the single-head softmax catastrophically forgets in both models because the Task1 output bias is driven negative; the mask isolates the experiment to hidden-representation forgetting, which is where LWTA acts |
| 2 hidden layers (paper used 2-3) | Faster training; same qualitative result |
| Hidden width 400 (paper used 512-1000) | Faster training |
| LWTA block size k=2 | Matches one of the paper’s settings (paper also reports k=4); k=4 was tried and gave noisier results in our small-net regime |
| SGD with momentum 0.9, no dropout | Original combined LWTA with dropout for the catastrophic-forgetting study; we strip dropout to isolate the activation effect |
| Task split: classes 0-4 then 5-9 (rather than permuted MNIST) | Permuted MNIST gave very noisy contrast at this scale (some seeds had ReLU forget more, some less). The class-disjoint split with multi-head output gives a cleaner signal |
Open questions / next experiments
-
High seed variance. At hidden=400 / k=2 / 5+5 epochs the LWTA advantage is ~3× at seed 0 but only ~1.05× in the 10-seed mean. The per-seed standard deviation (0.028) is larger than the mean improvement (0.002 difference). This is the small-network regime. The paper’s numbers were on hidden=512×3 networks trained for many more epochs. Re-running at hidden=800-1024, depth=3 and 50+ epochs/task would test whether the gap is consistent at the paper’s scale.
-
Does specialisation emerge faster with auxiliary regularisation? The paper combined LWTA with dropout. Adding dropout might encourage distinct LWTA blocks to specialise on Task1 vs Task2 features earlier in Task1 training, reducing the seed-level variance.
-
Permuted MNIST is harder. Our initial attempts on permuted MNIST (Task2 = pixel-permuted Task1) gave inconsistent contrast. The paper reports clear LWTA improvements on permuted MNIST but uses much longer training. Worth re-running once the budget allows.
-
What does the winner pattern look like across the layers? We only visualise winner frequencies on the first hidden layer. The specialisation hypothesis predicts that deeper LWTA layers are more strongly task-segregated than the first (which sees raw pixels and has to compute generic features). A v2 viz could plot
winner_freqfor each LWTA layer. -
ByteDMD instrumentation (v2 of this catalog). LWTA only fires
1/kof its hidden units per input but reads / writes the entire pre-activation buffer to compute the per-block max. Whether the data movement saves anything under the Dally model – versus simply reducing the dense matmul – is the v2 question.