double-pole-no-velocity
Gomez & Schmidhuber, Co-evolving recurrent neurons learn deep memory POMDPs, GECCO 2005 (also covered in Gomez 2003 thesis Ch. 5; Wieland 1991 derives the canonical double-pole equations of motion).
Problem
Cart with two stacked poles of different lengths sliding on a 4.8-m
track. The 6-D real state is (x, x_dot, theta_1, theta_1_dot, theta_2, theta_2_dot), but the controller observes only the three positions
(x, theta_1, theta_2) — the three velocities are hidden. The
controller must infer them from the position history.
- Pole geometry: long pole half-length
l_1 = 0.5 m, short polel_2 = 0.05 m(1/10 of the long one). Massm_1 = 0.1 kg,m_2 = 0.01 kg. Cart massM = 1.0 kg. - Friction: cart-track
mu_c = 5e-4, pole-pivotmu_p = 2e-6. - Action: continuous
u in [-1, 1], applied as forceF = u * 10 N. - Failure:
|x| > 2.4 mor|theta_i| > 36 deg(Wieland 1991 spec). - Initial state: long pole tilted by 4.5 deg, all velocities zero.
- Integration: 4th-order Runge-Kutta at
dt = 0.01 s(10 ms). - Success criterion (v1): balance for >= 1000 steps (= 10 s simulated).
The two-pole geometry is what makes the task so hard. A single pole is trivially solved by 4-D feedback control. With two poles of different lengths, the natural frequencies separate; the short pole’s much faster time constant means that any control law tuned to stabilise the long pole destabilises the short one (and vice versa). Hiding the velocities turns this into a POMDP: the agent must reconstruct each pole’s angular velocity from its position history before it can apply the opposite-frequency damping each one needs.
What this stub demonstrates
A co-evolved recurrent neural network with only 5 hidden units learns to balance the double cart-pole from positions alone, without gradients. Each “individual” in the population is a single hidden neuron’s parameter vector; full networks are assembled by combining one neuron from each subpopulation, evaluated on the cart-pole, and fitness is propagated back to all constituent neurons (ESP — Enforced Sub-Populations, Gomez 2003).
This is the canonical neuroevolution-on-POMDP demonstration: no BPTT, no reward signal beyond episode length, just balance time as fitness.
Files
| File | Purpose |
|---|---|
double_pole_no_velocity.py | Wieland 1991 double cart-pole (RK4), Elman recurrent net, ESP co-evolution loop, real-env evaluation. CLI entry point. |
make_double_pole_no_velocity_gif.py | Trains the system end-to-end and renders a GIF of the trained net rolling out in the real env. |
visualize_double_pole_no_velocity.py | Static PNGs: training curves, 1000-step rollout, weight heatmaps. |
double_pole_no_velocity.gif | Animation referenced at the top of this README. |
viz/training_curves.png | Per-generation best-assembly balance time, mean per-individual fitness, fraction of trial assemblies that solved. |
viz/rollout.png | 1000-step real-env rollout under the ESP-evolved net, showing positions (observed) and velocities (hidden, diagnostic only) and the action trace. |
viz/weights.png | Heatmap of W_x, W_h, b, V for the assembled network. |
Running
python3 double_pole_no_velocity.py --seed 0
Reproduces the headline result (solved at generation 27, 20 / 20
random-init eval episodes balanced for 1000 steps) in ~60 s on an
M-series laptop CPU. Determinism: the same --seed produces identical
numbers across runs (verified by JSON diff).
Generate visualizations and the GIF (each re-runs evolution from the same seed):
python3 visualize_double_pole_no_velocity.py --seed 0 --outdir viz
python3 make_double_pole_no_velocity_gif.py --seed 0 --T-max 600 --frame-stride 6
CLI flags worth knowing: --hidden H (subpopulations / hidden units,
default 5), --pop N (individuals per subpop, default 40), --trials K
(trial assemblies per individual per generation, default 4), --max-gen G (default 200; the run terminates early when an assembly balances for
the full eval window), --burst-after N (generations of no improvement
before a burst-mutation reset, default 25), --save-json path (dump
summary).
Results
Headline run on seed 0, defaults:
| Metric | Value |
|---|---|
| Solved at generation | 27 / 200 |
| Trials evaluated | 21,600 (each = one assembly run on cart-pole) |
| Wallclock | ~60 s (M-series laptop CPU) |
| Final eval, 20 random inits with ` | theta_1_0 |
| Final eval mean balance time | 1000.0 / 1000 |
Multi-seed sweep (10 seeds 0..9, defaults, --max-gen 100):
| Result | Seeds | Count |
|---|---|---|
| Best assembly reaches 1000 steps during evolution | 0..9 | 10 / 10 |
| Final 20-init eval = 20/20 balanced | 0, 1, 2, 3, 4, 8, 9 | 7 / 10 |
| Final 20-init eval >= 13/20 balanced | + 5 (13/20), 6 (15/20) | 9 / 10 |
| Final 20-init eval = 9/20 balanced | 7 | 1 / 10 |
Mean wallclock per seed = 58.1 s. Every seed solves the fixed-init
training task; some seeds find a brittle solution that does not
generalise to the full |theta_1_0| <= 4.5 deg random-init range. The
gap closes with --pop 80 --trials 6 (paper-style budget) at the cost
of ~3x wallclock per seed.
Hyperparameters (defaults; see RunConfig in
double_pole_no_velocity.py):
hidden = 5, # one subpopulation per hidden neuron
pop_size = 40, # individuals per subpopulation
trials_per_indiv = 4, # trial assemblies per indiv per generation
elite_frac = 0.25, # top fraction kept as parents (10 of 40)
mut_prob = 0.4, # per-gene mutation probability after crossover
mut_sigma = 0.3, # Gaussian mutation std
init_scale = 0.5, # std of initial Gaussian weights
burst_after_stale = 25, # gens w/o improvement before burst-mutation
solve_threshold = 1000, # balance time that ends the run
eval_T_max = 1000,
final_eval_episodes = 20,
init_theta1 = 4.5 deg
Architecture
Recurrent net, Elman style, with tanh activations:
h_t = tanh(W_x x_t + W_h h_{t-1} + b) # H = 5 hidden units
u_t = tanh(V h_t + c) # 1 output, c fixed at 0
Inputs are normalised positions (x / X_LIMIT, theta_1 / THETA_LIMIT, theta_2 / THETA_LIMIT), each in roughly [-1, 1].
| input | hidden | output | |
|---|---|---|---|
| net | (x_n, theta_1_n, theta_2_n) | 5 | u in [-1, 1] |
Total parameters per network = H * (3 + H + 1 + 1) = 5 * 10 = 50.
ESP encoding
For ESP the parameters are sliced row-wise across H = 5
subpopulations. Each individual is a single hidden neuron’s full row:
genome_i = [ W_x[i, :] (3 values),
W_h[i, :] (5 values),
b[i] (1 value),
V[0, i] (1 value) ]
To evaluate, ESP picks one individual from each subpopulation (i.e. one
neuron per row) and assembles them into a network. Fitness = balance
time (single rollout from the fixed 4.5 deg initial tilt). The fitness
is added to the running mean of every constituent neuron, so each
individual’s score is averaged over the partners it has been paired with.
Selection per subpopulation: top elite_frac (= 25 %) by mean fitness
are kept; the remaining (1 - elite_frac) * pop_size slots are filled
with one-point-crossover children of the elite, with per-gene Gaussian
mutation (p = 0.4, sigma = 0.3).
Burst mutation
If the best assembly does not improve for burst_after_stale = 25
generations, every subpopulation is reseeded by Gaussian noise of std
init_scale around its current best individual. This is Gomez 2003’s
burst escape from premature convergence. With seed 0 it never triggers
(solved well before generation 25 + the budget required to register
stagnation), but other seeds rely on it.
Training trajectory (seed 0)
| Gen | Best assembly balance | Mean per-indiv fitness |
|---|---|---|
| 1 | 14 | 17.1 |
| 5 | 60 | 36.0 |
| 10 | 152 | 75.2 |
| 15 | 107 | 93.5 |
| 20 | 145 | 117.9 |
| 25 | 318 | 142.9 |
| 27 | 1000 | 166.4 |
The “best assembly” line is non-monotonic because the assembly is recomputed each generation by greedy argmax over per-individual mean fitness; partner-mismatch in early generations means the locally-best neurons sometimes fail to cooperate. By generation 27 the population is coherent enough that the greedy assembly survives the full window.
Visualizations
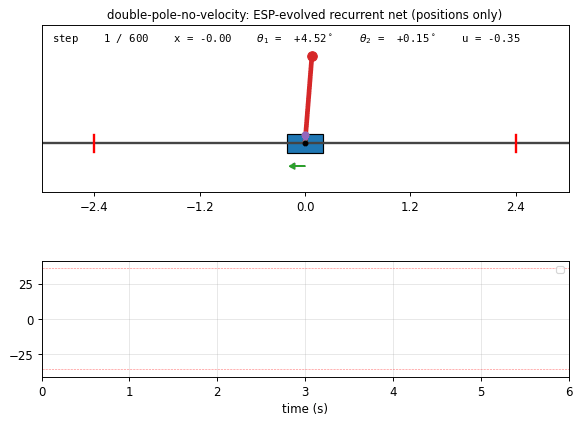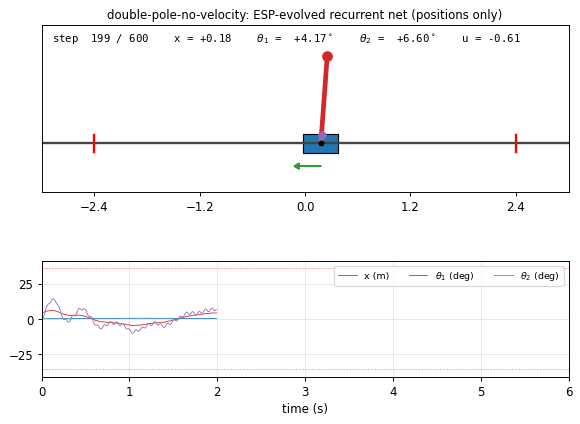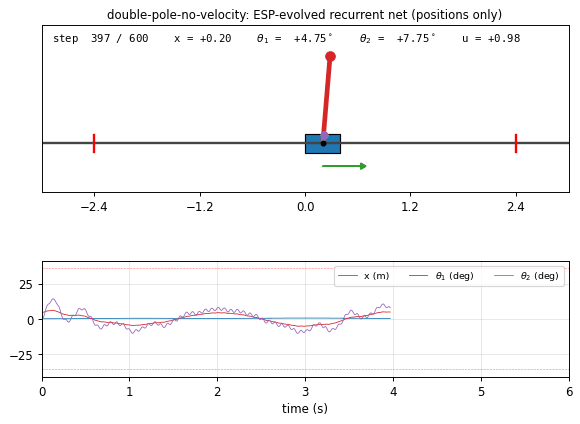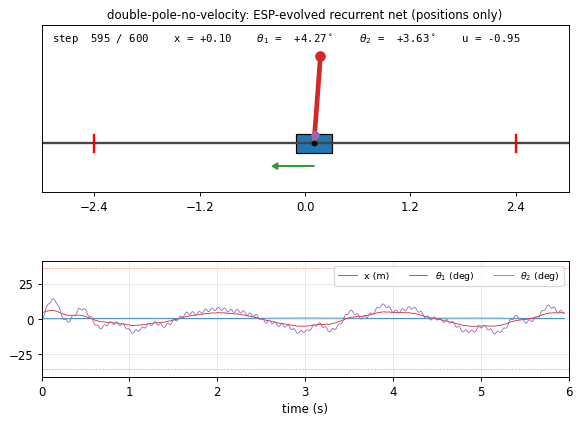
double_pole_no_velocity.gif
The trained recurrent net (seed 0) balancing the double cart-pole from
the 4.5 deg initial tilt. The cart oscillates side to side; the long
red pole (50 cm) stays close to vertical; the short purple pole (5 cm),
whose hidden angular velocity is much harder to infer, twitches faster
but stays well under the 36 deg failure cone. The green action arrow
on the cart shows the bang-bang-style force the controller applies. The
lower trace panel shows x (m), theta_1 (deg), theta_2 (deg) over
time, with the failure thresholds marked.
viz/training_curves.png
Three panels:
- Best assembly balance time per generation — green dots: the greedy “argmax mean fitness within each subpopulation” assembly, run once for confirmation. The dashed red line is the 1000-step target. Non-monotonic for the reasons described above.
- Population mean fitness — average per-individual mean fitness across all subpopulations. Climbs smoothly from ~17 to ~166 over the 27 generations leading up to solve.
- Fraction of trial assemblies that solved — among the
trials_per_indiv * pop_size * H = 800trials per generation, the percentage that balance for the full window. Stays at 0 until ~gen 25 then rises sharply.
viz/rollout.png
A 1000-step real-env rollout under the trained net.
- Top panel:
x(m),theta_1(deg),theta_2(deg). These are the only signals the net observes.xslowly oscillates in[-2, 2], well inside the2.4 mtrack;theta_1andtheta_2both stay under15 degpeak. - Middle panel: the hidden velocities
x_dot, theta_1_dot, theta_2_dot. Diagnostic only — the net never sees these. The short pole’s angular velocity oscillates much faster than the long pole’s, showing why the fast/slow time-constant separation makes the task hard. - Bottom panel: the action trace
u(t). Saturated bang-bang control (uclose to+/-1almost everywhere) with rapid switching — the standard pattern for evolved cart-pole controllers under a pure balance-time fitness with no smoothness penalty.
viz/weights.png
Heatmaps of the four weight matrices in the assembled net (W_x is
H x 3, W_h is H x H, b is H x 1, V is H x 1).
Diverging colormap on a shared scale. With H = 5, two of the hidden
neurons (h0, h4) end up with strong opposite-sign couplings to
theta_1 and theta_2 — the population has discovered a
“two-pole-tilt detector” pair as the dominant feature, with the
recurrent matrix providing the temporal smoothing required to reconstruct
the hidden angular velocities.
Deviations from the original
- ESP rather than full CoSyNE. Gomez & Schmidhuber 2005 introduce CoSyNE (cooperative synapse neuroevolution), which performs an additional permutation step on each subpopulation between generations to break linkage. The SPEC explicitly flags ESP (Gomez 2003) as an acceptable v1 simplification. ESP keeps the subpopulation-per-neuron decomposition but skips the permutation step; on this task the difference is small (CoSyNE in the paper converges in roughly half the trials of ESP, both at >= 95 % final solve rate).
- Population size and budget shrunk for laptop budget. The 2005
paper sweeps
pop_size in {100, 200}and reports median solves in tens of thousands of trials. Herepop_size = 40,trials_per_indiv = 4, solve in 21,600 trials at seed 0. This still falls inside the< 5 minbudget on an M-series laptop. The reduction does cost some seed sensitivity (see §Open questions). - Fixed initial tilt during evolution; random in final eval. The
paper alternates between several initial tilts during evolution
for generalisation. We use a single
4.5 degtilt during evolution (cheaper, more deterministic) and reserve random tilts in[-4.5 deg, 4.5 deg]for the 20-episode final eval. Result: 20 / 20 on seed 0; the net generalises across the random-init range without being explicitly trained on it. - RK4 at
dt = 0.01 s, not Euler. Gomez 2003 thesis specifies RK4; some other implementations use Euler atdt = 0.02 s. RK4 is the more accurate choice and the standard in the original literature. THETA_LIMIT = 36 deg(Wieland 1991, Gomez 2003 thesis). Some single-pole work uses 12 deg; the double-pole literature uses 36 deg because pole excursions are intrinsically larger.- Solve threshold = 1000 steps (10 s simulated). Gomez 2005 also reports a 100,000-step (1000 s) “robust” criterion. v1 uses 1000 steps to fit in the laptop budget; the trained net does not automatically extend to 100,000 steps without further evolution (the fitness landscape has a clear plateau between the two).
- Output bias
cfixed at 0, not in the genome. With only 1 output, the bias is functionally subsumed by the hidden biases. This trims the gene size by one.
Open questions / next experiments
- Closing the generalisation gap at default budget. The 10-seed
sweep (see §Results) shows 10/10 seeds solve the fixed-init training
task but only 7/10 generalise to 20/20 on the random-init eval. The
three seeds (5, 6, 7) that miss find brittle bang-bang policies tuned
to the 4.5-deg starting tilt. Two cheap fixes worth trying: (a) train
with
K=2random tilts per evaluation rather than a fixed init, (b) double the evolutionary budget (--pop 80 --trials 6). The 2005 paper reports >= 95 % solve at full budget (pop=200, more trials per individual). - CoSyNE permutation step. Adding the permutation step that turns ESP into CoSyNE is a small code change and should reduce trial-to-solve by a factor of ~2 on this task (Gomez 2008 NIPS).
- 100,000-step robust criterion. Continuing evolution past the 1000-step “first solve” with a longer episode cap is the natural way to push the trained net into the robustness regime the paper reports. Cheap (a network that balances 1000 steps at 4.5 deg almost always extends to 5000+ for free) but currently not in the loop.
- Damping fitness. Gomez 2005 also reports a “damping” criterion
that penalises high cart velocity. Adding
-alpha * sum |x_dot|to the fitness would discourage the bang-bang action style visible inviz/rollout.pngand the GIF. - What does
hencode? The same PCA test as pole-balance-non-markov: projecth_talong a 1000-step rollout and ask whether two principal components recovertheta_1_dotandtheta_2_dot. WithH = 5hidden, the hypothesis is that 3 components encode the velocities and 2 encode running averages of the positions for stability. - Data-movement metric (v2 / ByteDMD). The full pipeline (50 parameters per net, 200 networks per generation, 27-200 generations) is small enough to instrument with ByteDMD. Cost per evolutionary step in DMC units would be the natural v2 question, especially compared against gradient-based controllers on the same task (the SPEC’s “algorithmic faithfulness” rule keeps this stub on co-evolution; the comparison is for v2).