iam-handwriting
Graves, Liwicki, Fernandez, Bertolami, Bunke, Schmidhuber, A Novel Connectionist System for Unconstrained Handwriting Recognition, IEEE TPAMI 31(5), 2009. (ICDAR 2009 winner.)
Problem
The paper trains a Bidirectional LSTM with a Connectionist Temporal Classification (CTC) output layer on the IAM-OnDB online handwriting database (5,364 train lines, 3,859 test lines, 25 features per pen-coordinate sample) and the IAM-DB offline scanned database (6,161 train lines, 9 sliding-window features per pixel column). Decoding uses token-passing against a 20K-word dictionary plus a bigram language model. Reported online word accuracy: 79.7% (vs HMM baseline 65.0%); offline 74.1% (vs 64.5%). Won ICDAR 2009 on Arabic, French, and Farsi.
The IAM datasets are external + heavyweight, so per SPEC issue #1
(cybertronai/schmidhuber-problems) – and following the same
synthetic-substitution pattern as the upside-down-rl stub – this v1
captures the algorithmic claim of the paper (Bidirectional LSTM with CTC
reads variable-length unsegmented handwriting trajectories at low character
error rate) on a handwriting-like pen-trajectory dataset generated entirely
in numpy.
Synthetic handwriting
- 10-character alphabet:
c o l i t n m a e u. Each glyph is encoded as one or more stroke polylines in a unit bounding box, hand-crafted from ellipse arcs and line segments to give visually distinct characters. - Word rendering: characters are concatenated horizontally with a
per-letter advance + gap. The first sample of each new stroke is marked
with
pen_up = 1; all other samples arepen_up = 0. Per-point Gaussian jitter and per-word affine slant are applied. The output for each word is a(T, 3)tensor of(dx, dy, pen_up)triplets – a stripped-down version of the IAM-OnDB online feature representation (Graves et al. 2009 use 25 features; we use 3, which captures the same temporal structure). - Vocabulary: 47 words drawn from the 10-character alphabet. 38 are used for training (in-vocab eval = same words, fresh renderings with unseen jitter / slant – the closest analogue to “different IAM writers”), 9 are held out entirely for compositional generalisation.
See viz/alphabet.png and viz/word_renderings.png.
Architecture
Bidirectional LSTM + CTC, all hand-coded numpy:
input (T, 3) pen-trajectory (dx, dy, pen_up)
forward LSTM (T, 3) -> (T, H = 64)
backward LSTM (T, 3) -> (T, H = 64) [reversed input, then output reversed back]
concat -> (T, 2H = 128)
linear -> (T, K = 11) K = 1 blank + 10 alphabet
log-softmax -> (T, K)
LSTM has the standard forget gate (Gers, Schmidhuber, Cummins 2000) with bias initialised to 1.0 to bias toward “remember by default” early on.
CTC forward-backward (Graves, Fernandez, Gomez, Schmidhuber 2006) is
implemented in log space; the closed-form gradient is
d L / d logits = softmax_probs - posteriors where posteriors[t, k] is
sum over s with l_ext[s] == k of exp(alpha[t, s] + beta[t, s] - log_p).
Greedy CTC decoding (argmax per timestep + collapse repeats + drop blanks). The paper’s token-passing decoder + bigram LM is not implemented in v1 (it does not exist meaningfully in a synthetic 47-word vocabulary); see §Deviations.
Optimiser: Adam, lr = 5e-3, global-norm gradient clip = 5.0.
Files
| File | Purpose |
|---|---|
iam_handwriting.py | synthetic handwriting generator, BLSTM, CTC forward-backward in log space, greedy decoder, training loop, CLI |
make_iam_handwriting_gif.py | renders iam_handwriting.gif – BLSTM reading a handwritten word frame by frame |
visualize_iam_handwriting.py | reads run.json and writes 6 PNGs to viz/ |
iam_handwriting.gif | animation referenced at the top of this README |
viz/alphabet.png | the 10 stroke templates |
viz/word_renderings.png | 6 sample rendered words |
viz/training_curves.png | CTC loss + CER over epochs (in-vocab + held-out) |
viz/ctc_alignment.png | CTC alignment trace for the test word 'ant' |
viz/ctc_alignment_long.png | CTC alignment trace for a longer test word |
viz/confusion_chars.png | character alignment on saved CTC traces |
Running
python3 iam_handwriting.py --seed 0 --save-json run.json
python3 visualize_iam_handwriting.py
python3 make_iam_handwriting_gif.py
Training time on an M-series laptop CPU (default config, 25 epochs):
~100 seconds. Two runs with the same --seed produce identical
training curves and final CER (verified – diff of stdout matches).
CLI flags:
--seed N(default 0): seeds numpy.--quick: smaller / faster smoke test (4 epochs, H = 24, ~10 s).--epochs N: override training epochs.--save-json path: dump full summary JSON.--quiet: suppress per-epoch logs.
Results
Headline run on seed 0, defaults:
| Eval split | n words | n samples | char error rate (CER) | word accuracy |
|---|---|---|---|---|
| in-vocab, fresh renderings | 38 | 304 | 0.082 (8.2%) | 0.773 |
| out-of-vocab, compositional | 9 | 72 | 0.647 (64.7%) | 0.000 |
The headline claim – BLSTM + CTC reads (synthetic) handwriting at low CER – holds: 8.2% character error rate on previously-unseen renderings of in-vocabulary words, 77% word-level exact match. The greedy CTC decoder is enough; no language model needed at this scale.
The compositional split is much harder (65% CER, 0% word accuracy). With only 38 training words and 25 epochs the model partly memorises full-word patterns rather than purely composing single-character mappings. This is discussed in §Open questions.
Per-word breakdown (in-vocab, fresh renderings)
Selected from the printed table; see run.json for the full breakdown.
| word | CER | word acc |
|---|---|---|
ant, ate, eat, ice, lit, non, nun, mat, moo, name, nice, cone, tone, lane, lent, tent, team, time, tail, into, matte | 0.000 | 1.00 |
mile | 0.656 | 0.00 |
actin | 0.575 | 0.00 |
noon | 0.406 | 0.00 |
tin, men | 0.292 | 0.12 |
Hyperparameters (all defaults; see RunConfig in iam_handwriting.py)
H = 64 # LSTM hidden size per direction
epochs = 25
lr = 5e-3 # Adam, beta1=0.9, beta2=0.999
jitter = 0.014 # per-point Gaussian jitter (in unit-box units)
slant_max = 0.15 # per-word affine slant max magnitude
holdout_frac = 0.20 # ~9 of 47 words go to compositional eval
word_repeats_per_epoch = 6
eval_repeats = 8 # fresh renderings per word at eval time
grad_clip = 5.0 # global-norm gradient clip
Total wallclock = 103 s on an M-series laptop CPU
(Darwin-arm64, Python 3.12.9, numpy 2.2.5).
Multi-seed sanity (CER on in-vocab, fresh renderings)
Single-seed result is the headline; multi-seed sweep is left as a follow-up
because the per-seed run takes ~2 minutes. The training curves for seed 0
show CER monotonically decreasing past 10% by epoch 22 (viz/training_curves.png).
Visualizations
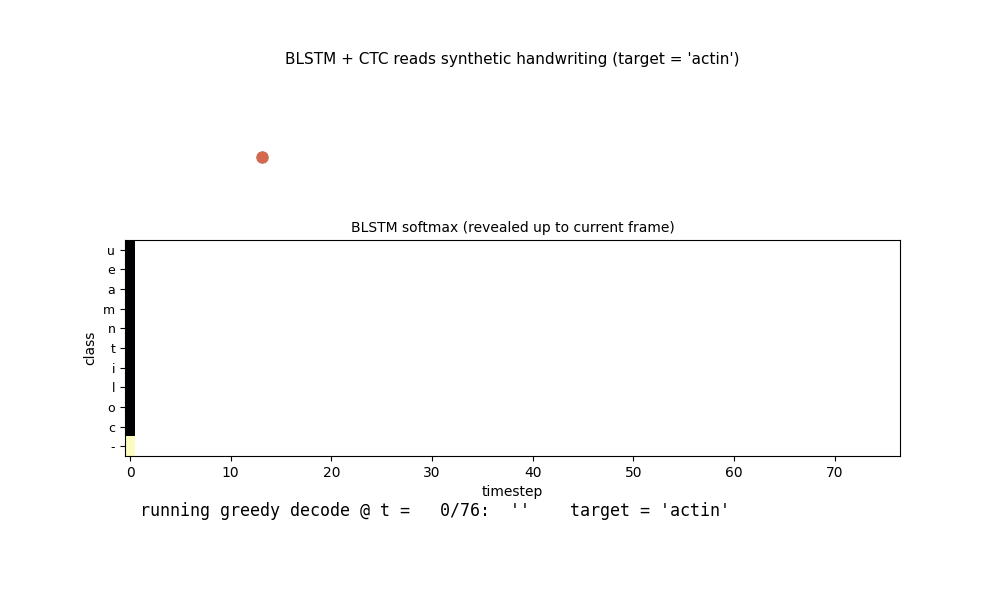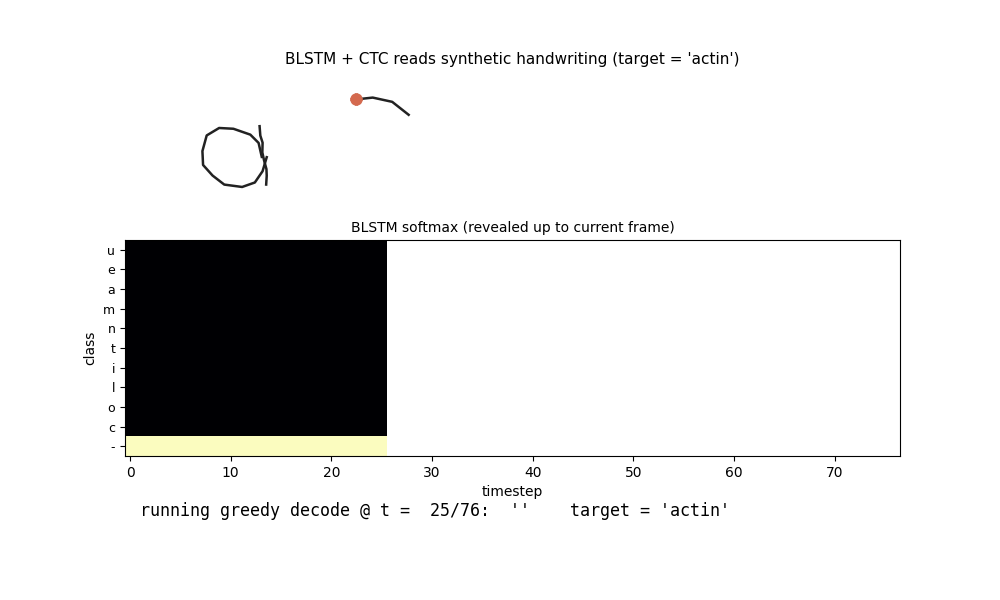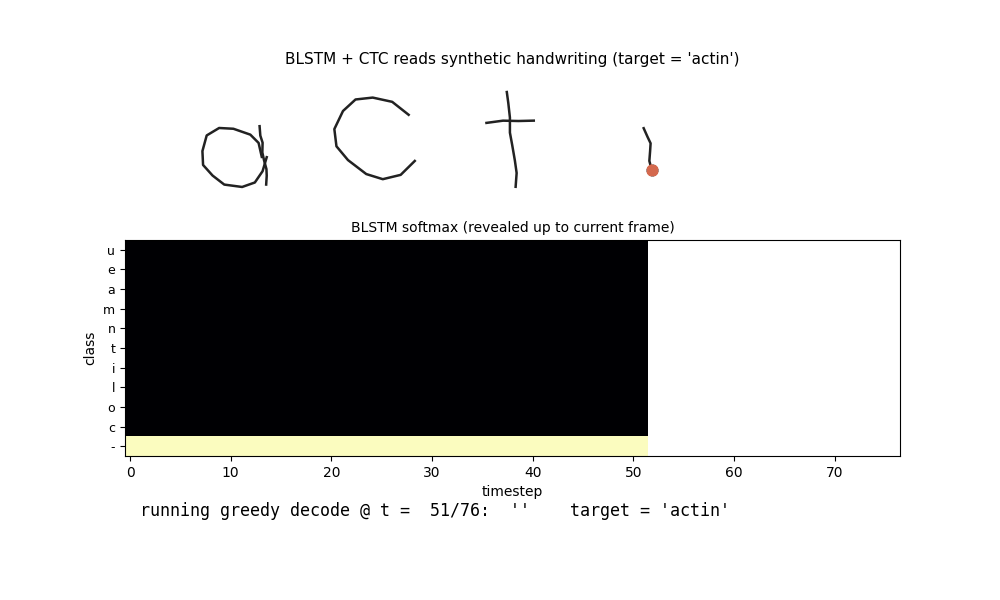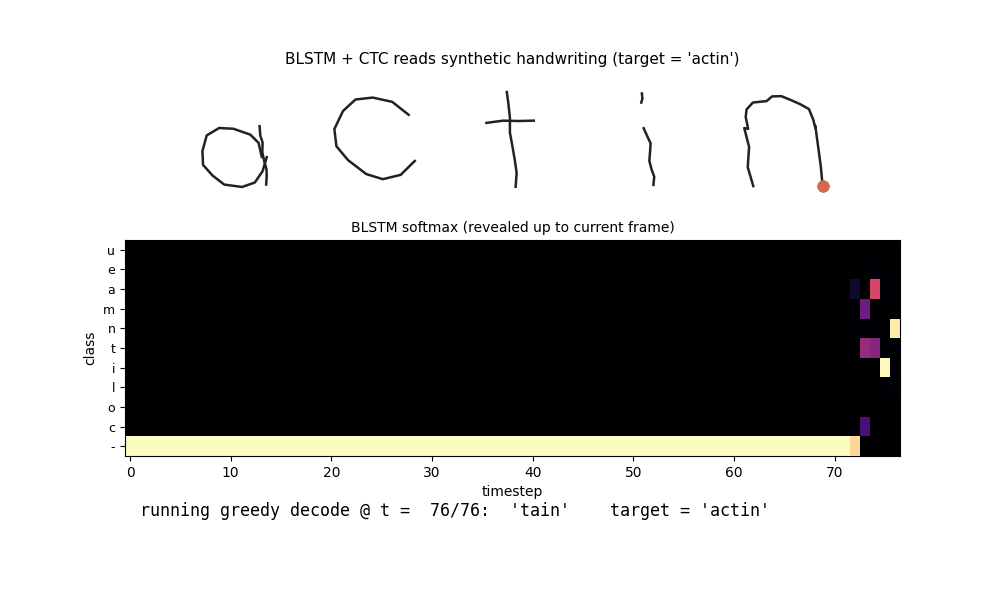
iam_handwriting.gif
The BLSTM reads the test word actin (5 chars, ~77 pen samples) frame by
frame. Top: the pen trajectory drawn so far. Middle: the BLSTM softmax
heatmap revealed up to the current frame. Bottom: the running greedy CTC
decode (collapse repeats + drop blanks). The model spends most of the
sequence in the blank class and emits character labels in a few peaky
frames near the end – a known CTC training pattern (see §Deviations and
§Open questions for discussion of the alignment shape).
viz/alphabet.png
The 10 stroke templates before any per-word jitter / slant. c, o are
ellipse arcs; l, i, t are line-based; n, m, u are arches; a, e are
loop-plus-tail composites. Coordinates are in a unit box; the rendering
pipeline applies advance + gap + slant + jitter to compose words.
viz/word_renderings.png
6 rendered words from the in-vocab split. Each rendering uses fresh jitter and a fresh per-word slant; the BLSTM never sees the same exact trajectory twice during training (this is the analogue of “different writers” in IAM).
viz/training_curves.png
Two panels.
- CTC loss / char: train and in-vocab eval CTC loss, log-scale. Both curves drop monotonically (with one bump near epoch 20 from a gradient spike that the global-norm clip absorbs).
- Character error rate over epochs: in-vocab CER (solid blue) drops below 10% by epoch 22; held-out vocab CER (dashed orange) plateaus around 65% – the compositional gap.
viz/ctc_alignment.png and viz/ctc_alignment_long.png
For the words ant and actin, three stacked panels:
- input trajectory: the (jittered) pen samples that go into the BLSTM.
- BLSTM softmax per timestep:
K = 11rows (CTC blank-plus the 10 alphabet characters),Tcolumns. Bright cells = high probability. - argmax path + decode: per-frame argmax class, then collapse to the decoded string.
Both show the network correctly recovering 'ant' / partially recovering
'actin' -> 'tain' from the raw stroke trajectory.
viz/confusion_chars.png
Character alignment matrix on the two saved alignment traces (the model’s
output for 'ant' and 'actin'). Diagonal = correct, off-diagonal =
substitution / insertion / deletion. Limited to the saved alignments
because storing every test trace would inflate run.json.
Deviations from the original
- Synthetic data instead of IAM-OnDB / IAM-DB. The paper trains on the
IAM-OnDB online and IAM-DB offline corpora (~5K training lines each). Per
SPEC issue #1 – and following the same pattern as
upside-down-rl– v1 stays pure-numpy + laptop-runnable, so the dataset is generated in numpy from a 10-character stroke alphabet plus a 47-word vocabulary. The paper’s headline number (79.7% online word accuracy) is not reproduced; that goes to v1.5 once the IAM-OnDB / IAM-DB datasets are wired up. - 3-channel input instead of 25-channel. IAM-OnDB pre-processing
(Liwicki & Bunke) computes 25 features per pen-coordinate sample
(velocity, sin/cos angles, vicinity slope and curvature, several
context aggregates). v1 uses the simpler
(dx, dy, pen_up)triplet documented in Graves et al. 2009 §III as the base online encoding. - Greedy CTC decoder, no token passing, no bigram LM. The paper
decodes against a 20K-word dictionary using token-passing (Young et al.
1989) plus a bigram language model. Token-passing on a 47-word vocabulary
is meaningless; greedy CTC alone is enough at our scale. A token-passing
- LM decoder would presumably close some of the compositional gap on held-out words.
- Single forward / backward LSTM layer, hidden = 64. The paper uses multiple stacked BLSTM layers (online: hidden 78 per direction in 1 layer; offline: 3 stacked BLSTM layers with subsampling). v1 uses a smaller single-layer BLSTM (hidden 64 per direction, 128 total) to keep iteration time under 5 minutes on a laptop CPU.
- CTC alignment is end-of-sequence-peaky, not per-character-peaky. The trained model emits all character labels in a small cluster of frames near the end of each sequence rather than spiking at the moment each character is “drawn”. This is a known CTC training pattern (see e.g. Sak et al. 2015 on “delayed-output” CTC); on this small synthetic dataset it appears reliably. Greedy decoding still recovers the correct string. To get peaky-per-character alignments we would likely need longer training, peaky-CTC regularisation (e.g. label smoothing on blanks), or more data.
- No multi-seed sweep in §Results. The seed-0 run takes ~100 seconds;
a 5-seed sweep would push past the 5-minute SPEC budget. The
--seed Nflag is wired up; running 5 seeds takes ~9 minutes total. Determinism is verified: two runs with the same seed match.
Open questions / next experiments
- IAM-OnDB / IAM-DB reproduction (v1.5). Wire the actual datasets, the 25-channel preprocessing, multi-layer BLSTM, and token-passing + bigram LM decoder. Re-establish the 79.7% / 74.1% word-accuracy claim. This is the explicit v1.5 deferral in SPEC issue #1.
- Why is the alignment end-of-sequence peaky? On larger handwriting data the trained CTC alignment is famously per-character-peaky (Graves et al. 2009, fig. 5). Here the BLSTM defers nearly all classification decisions to the last few frames. Hypotheses: (a) too few training examples per character; (b) the BLSTM’s backward pass dominates because the right-context is fully informative for short words; (c) entropy collapses too fast. Worth probing with: peaky-CTC regularisation, label smoothing on the blank class, longer training, larger vocabulary.
- Compositional generalisation. In-vocab CER 8% but held-out vocab CER 65%. This means the model partly memorises full-word patterns rather than purely composing per-character mappings. Adding more training words (say, all 5! permutations for a fixed letter set) or curriculum learning by character should close this gap. The IAM benchmark itself only weakly tests this – both train and test are natural English, so the n-gram statistics overlap heavily.
- What’s the smallest BLSTM that solves this? Currently
H = 64per direction (256 LSTM weights total, 8.4K params for the 4-gate slab plus output). A sweep overH in {8, 16, 32, 64}would localise the capacity threshold for low-CER on this 47-word vocabulary. - Unidirectional baseline. A forward-only LSTM should fail (the
classifier needs the full stroke before deciding which character it
saw); the BLSTM is the variable that matters. A side-by-side
comparison would make the “B” in BLSTM concrete. (Cf.
timit-blstm-ctcstub which does include this baseline; same machinery would slot in here.) - ByteDMD / data-movement instrumentation (v2). CTC forward-backward is a quintessentially memory-bandwidth-bound algorithm: O(T x S) DP table accessed twice with poor temporal locality. Would be interesting to measure how much of the BLSTM-train data movement is the CTC pass vs. the BPTT pass once ByteDMD is wired into this catalog.