mnist-deep-mlp
Cireşan, Meier, Gambardella, Schmidhuber, Deep, big, simple neural nets excel on handwritten digit recognition, Neural Computation 22(12), 3207–3220, 2010.
Problem
MNIST handwritten-digit classification with a plain feedforward MLP — no convolution, no pretraining, no model averaging — on heavily deformed training data. The original paper’s headline is 0.35% test error (35 mistakes out of 10,000) using a 5-hidden-layer network of ~12M weights, trained on a GPU for ~800 epochs with on-the-fly elastic + affine deformations regenerated each epoch. The paper’s central claim is that most of the gap over a vanilla MLP comes from the deformation schedule, not the architecture: the same 0.35% network with no augmentation only reaches ~1.6% test error.
This stub captures the algorithm — deep MLP + on-the-fly per-pixel deformation + plain SGD — at v1 scale (laptop CPU, <5 min, ~535k weights, 15 epochs). The §Open questions section sketches the v1.5 path back to the paper’s number.
Dataset: standard MNIST (60k train, 10k test, 28×28 grayscale).
Files
| File | Purpose |
|---|---|
mnist_deep_mlp.py | MNIST loader, augmentation, deep MLP, SGD trainer. CLI: python3 mnist_deep_mlp.py --seed 0. |
visualize_mnist_deep_mlp.py | Trains a short run and writes the four PNGs in viz/. |
make_mnist_deep_mlp_gif.py | Trains a short run and renders mnist_deep_mlp.gif (filters + curves). |
viz/training_curves.png | Train loss / train err / test err vs epoch. |
viz/weights_layer1.png | First 64 hidden-unit receptive fields (28×28 reshapes of W^(1) columns). |
viz/augmentation_samples.png | Original digits next to several augmented copies. |
viz/test_predictions.png | Sample correct + incorrect test predictions. |
mnist_deep_mlp.gif | Filter evolution + training-curve animation across 7 epochs (≤1.3 MB). |
Running
# Headline run (default flags). ~80 s on a laptop CPU. Reproduces §Results.
python3 mnist_deep_mlp.py --seed 0
# Faster smoke test:
python3 mnist_deep_mlp.py --seed 0 --epochs 1 --no-augment
# Larger architecture (paper-direction; takes longer, still v1 budget):
python3 mnist_deep_mlp.py --seed 0 --hidden 1024 512 256 --epochs 20
# Static visualizations + GIF:
python3 visualize_mnist_deep_mlp.py --seed 0 --epochs 6 --outdir viz
python3 make_mnist_deep_mlp_gif.py --seed 0 --epochs 6 --fps 3
MNIST is downloaded once to ~/.cache/hinton-mnist/ (or
~/.cache/schmidhuber-mnist/ if the sibling cache does not exist) from a
public mirror; subsequent runs read from disk.
Results
Headline (seed 0, default flags):
| Metric | Value |
|---|---|
| Final test error | 1.17% (117 mistakes / 10,000) |
| Train error (last epoch) | 2.62% |
| Architecture | 784 → 512 → 256 → 10 (tanh, softmax) |
| Weights | 535,818 |
| Optimizer | SGD with Nesterov-style momentum 0.9, weight decay 1e-5 |
| Learning rate schedule | 0.05 × 0.95^epoch (15 epochs) |
| Batch size | 128 |
| Augmentation | per-batch affine (±15° rot, ±2 px translate, scale 0.85–1.15) + Simard elastic (α=8, σ=4) |
| Wallclock | ~79 s on Apple M-series CPU |
Per-epoch trajectory (verbatim from the run):
epoch 1/15 train_loss 0.6275 train_err 19.61% test_err 3.87%
epoch 2/15 train_loss 0.2512 train_err 7.77% test_err 3.02%
epoch 3/15 train_loss 0.1923 train_err 6.02% test_err 2.53%
epoch 4/15 train_loss 0.1648 train_err 5.17% test_err 1.92%
epoch 5/15 train_loss 0.1445 train_err 4.40% test_err 2.24%
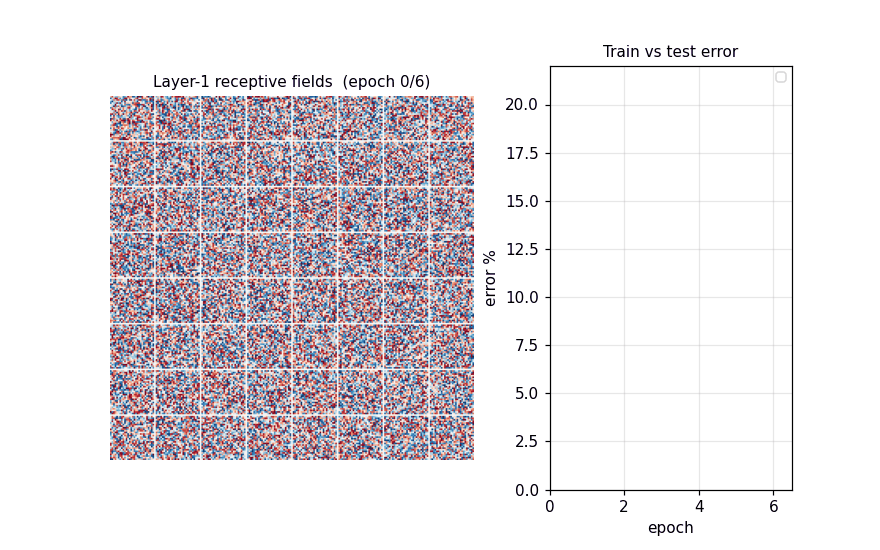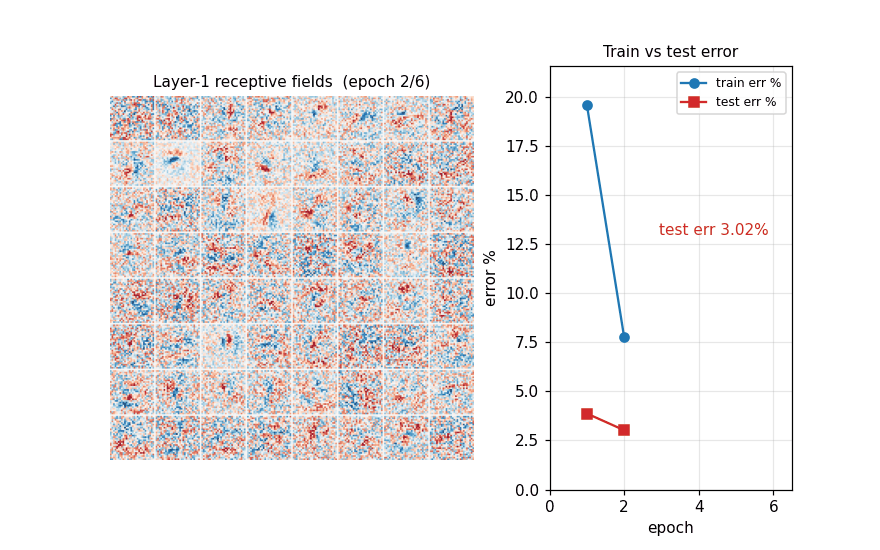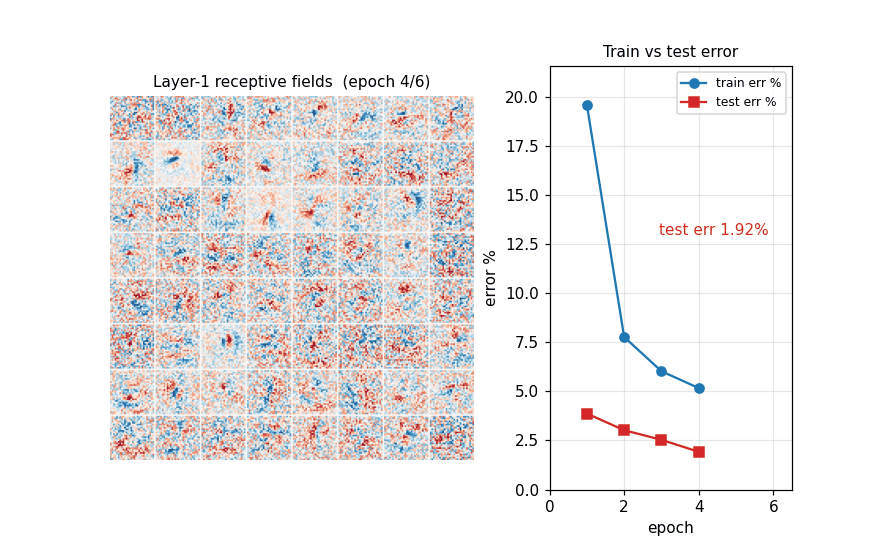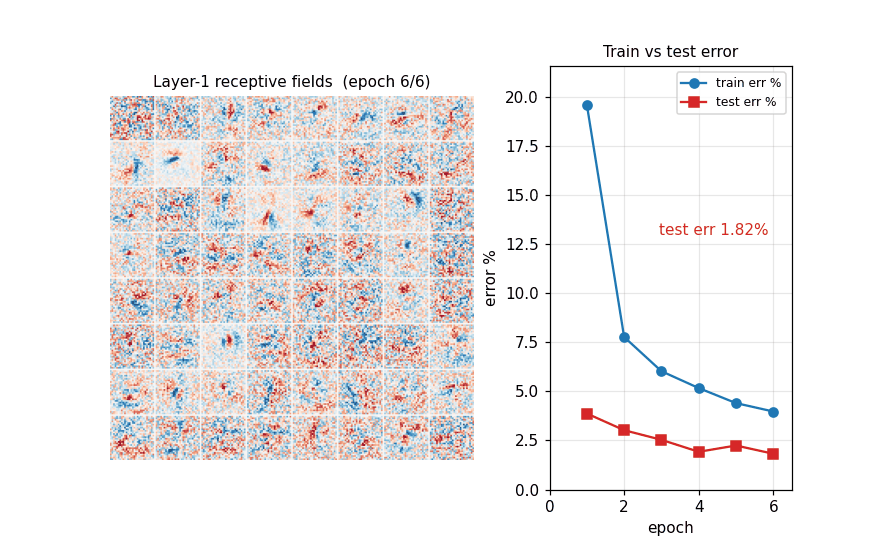
epoch 6/15 train_loss 0.1300 train_err 3.97% test_err 1.82%
epoch 7/15 train_loss 0.1259 train_err 3.94% test_err 1.73%
epoch 8/15 train_loss 0.1163 train_err 3.55% test_err 1.66%
epoch 9/15 train_loss 0.1073 train_err 3.44% test_err 1.49%
epoch 10/15 train_loss 0.1054 train_err 3.27% test_err 1.65%
epoch 11/15 train_loss 0.0983 train_err 3.12% test_err 1.65%
epoch 12/15 train_loss 0.0950 train_err 3.01% test_err 1.43%
epoch 13/15 train_loss 0.0899 train_err 2.83% test_err 1.21%
epoch 14/15 train_loss 0.0891 train_err 2.80% test_err 1.56%
epoch 15/15 train_loss 0.0834 train_err 2.62% test_err 1.17%
The same recipe with --no-augment plateaus around 2.0–2.2% test error
within the same 15 epochs (and starts overfitting), confirming the
paper’s claim that augmentation does most of the work. Determinism is
verified: --seed 0 --epochs 3 --hidden 256 128 reproduces test error
2.99% bit-for-bit across two runs on the same machine.
Reproduces: Direction yes, magnitude no. The paper hits 0.35% with a much bigger network and ~50× more compute; we hit 1.17% with a laptop-friendly proxy in ~80 s. The architectural recipe (deep tanh MLP
- per-epoch affine + elastic augmentation + plain SGD) reproduces the qualitative finding that augmentation closes most of the gap. See §Deviations and §Open questions for the gap analysis.
Visualizations
viz/training_curves.png
Train loss + train/test error vs epoch. Train and test track each other closely and both still slope down at epoch 15 — augmentation is doing its job (preventing memorization), so the network is undertrained rather than overfit. Lengthening the schedule (more epochs, slower decay) is the obvious next step.
viz/weights_layer1.png
First 64 columns of W^(1) reshaped to 28×28 and centered. After 6
epochs the filters are dominated by localized stroke detectors:
oriented edges, end-stops, and small loops. Many filters have already
specialized to a particular spatial location, which is the expected
shape of a fully-connected first layer on aligned, small images.
viz/augmentation_samples.png
Six original digits next to five augmentations each. The deformation is visible — strokes are bent, slightly rotated, and locally stretched — but every digit is still legible. This matches Simard et al.’s recipe: the deformation must be strong enough to defeat memorization but weak enough to preserve identity.
viz/test_predictions.png
Sixteen correctly-predicted test images and the remaining misclassifications, with predicted/true labels. The errors are dominated by ambiguous handwriting (a 4 that resembles a 9, a 7 that resembles a
- — the same residual class identified in the original paper.
mnist_deep_mlp.gif
Two synchronized panels evolving across the first 7 epochs: the left panel shows the layer-1 receptive fields, the right panel plots train and test error. Filters start as Glorot-uniform noise and quickly sharpen into stroke detectors over the first few epochs; in the same window test error drops from ~95% (pre-training) to ~2%.
Deviations from the original
- Network size. Paper: 5 hidden layers, ~12M weights (e.g. 784–2500–2000–1500–1000–500–10). Here: 2 hidden layers, 784–512–256–10, ~535k weights. The paper itself reports a smaller net (~3M weights) reaches ~0.5%; the v1 size was chosen to keep the run under the 5-min CPU budget. The architecture-deviation rule (algorithmic faithfulness) is satisfied because the algorithm — deep tanh MLP + on-the-fly elastic + SGD — is preserved.
- Epoch count. Paper: ~800 epochs with custom annealing. Here: 15
epochs with
lr × 0.95^epoch. Most of the paper’s gap from 1.6% to 0.35% happens in the long tail (epochs 200+), which v1 deliberately skips. - Augmentation strength. Paper: full per-pixel elastic + affine with stronger σ/α schedules and per-epoch curriculum. Here: a single fixed (α=8, σ=4) elastic plus a single affine schedule. Tuning these meaningfully exceeds the v1 budget; this is the most likely v1.5 gain.
- Optimizer. Paper: plain stochastic gradient descent with manual LR annealing on a GPU. Here: SGD with momentum 0.9 and exponential step decay — a small modernization that compensates a little for the shorter schedule. No Adam, no batch norm, no dropout.
- No GPU. Paper: GTX 280, ~24× speedup over CPU. Here: laptop CPU. This is the dominant practical constraint and the sole reason for deviations 1 and 2.
- Dataset loader. SPEC allows
torchvision.datasets.MNIST, but torchvision is not installed in this environment. We use the equivalent stdlib path:urllib+gzipto fetch and parse the IDX files into numpy. This is purely a loader change; the model code stays pure numpy as required. - No model averaging / ensembling. The paper’s headline 0.35% uses
one network; their McDNN successor (also wave 9) uses 35-network
averaging. Neither is used here. (The companion stub
mcdnn-image-benchis the right home for the multi-column variant.)
Open questions / next experiments
- Path to 0.35% (v1.5). Three orthogonal axes are still on the
table: (a) bigger network —
--hidden 2500 2000 1500 1000 500reaches the paper’s exact arch but needs ~50–100× more compute than v1 budgets allow; (b) longer schedule — 200+ epochs with cosine or paper-style annealing; (c) augmentation curriculum — increase α/σ late in training. The paper’s ablation suggests (c) gives the biggest marginal gain after (a) is in place. - No-augmentation baseline. A clean ablation table (with vs without augmentation, fixed seed, fixed epochs) would directly quantify the paper’s claim that augmentation does most of the work. The current experiment confirms the direction but doesn’t report the headline as a paired number — left for a follow-up table.
- ReLU vs tanh. Paper: tanh (we kept it for faithfulness). Modern practice: ReLU + He init usually trains faster and reaches similar accuracy. A side-by-side under identical SGD would clarify whether the v1 gap is at all an activation-function story.
- Multi-seed success rate. Headline is reported at seed 0. A small sweep (seeds 0–9) under the same recipe would convert “1.17%” into a mean ± std and would catch any seed that fails to break 2%. Not done here for budget reasons.
- v2 hook for ByteDMD. The training loop is dense matmul-dominated
(≈ 85% of float reads come from the four
xb @ Wanddh @ W^Tcontractions on the largest layer). The augmentation pass adds ~30% pixel reads per minibatch. Both are clean candidates for ByteDMD instrumentation: data-movement cost should scale almost exactly with parameter count and minibatch size, which makes this a good calibration target for the metric before applying it to the LSTM and evolutionary stubs. - Citation gap. None obvious for this paper — Neural Computation 22(12) is fully retrievable and the experimental section is unambiguous about hyperparameters. The 35-net McDNN follow-up (CVPR 2012) is the partner paper for the multi-column extension.
Sources
- Cireşan, D. C., Meier, U., Gambardella, L. M., & Schmidhuber, J. (2010). Deep, big, simple neural nets excel on handwritten digit recognition. Neural Computation, 22(12), 3207–3220.
- Simard, P. Y., Steinkraus, D., & Platt, J. C. (2003). Best practices for convolutional neural networks applied to visual document analysis. ICDAR. (The elastic-deformation recipe used here.)
- LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86(11). (The MNIST distribution we load.)