hq-learning-pomdp
Wiering, M., & Schmidhuber, J. (1997). HQ-Learning. Adaptive Behavior, 6(2), 219–246. doi:10.1177/105971239700600202 | paper page: people.idsia.ch/~juergen/hq
Problem
HQ-learning is a hierarchical extension of Q(lambda) for partially-observable Markov decision problems (POMDPs). The system is an ordered sequence of M reactive sub-agents. Each sub-agent has its own Q-table and (except the last) an HQ-table that scores observations as candidate sub-goals. A control-transfer unit fires when the current observation matches the active sub-agent’s chosen sub-goal, handing control to the next sub-agent.
The headline experiment in the paper is a partially-observable maze (POM) with 62 free positions but only 9 distinct observations (the wall mask of the four neighbouring cells). The optimal policy is a 28-step path requiring at least three reactive sub-agents because the optimal action at the most common observation depends on which segment of the path the agent is in — a flat memoryless Q-learner cannot represent it.
Algorithm (paper eqs Q.1, Q.2, HQ.1, HQ.2, HQ.3)
For sub-agent i active during step t in trial:
Q.1 (mid-trial) Q_i(O_t, A_t) <- (1-aQ) Q_i + aQ * (R + gamma * V_j(O_{t+1}))
Q.2 (trial end) Q_i(O_T, A_T) <- (1-aQ) Q_i + aQ * R(S_T, A_T)
where V_j is taken under whichever sub-agent will act next (j = i if no
transfer, j = i+1 if the sub-goal was just reached). With Q(lambda) we
maintain a per-sub-agent eligibility trace e_i[o,a] (replacing trace) that
decays by gamma * lambda between updates.
For the HQ-table updates at trial end, with Δt_i the duration of sub-agent
i’s tenure and R_i the cumulative reward during it:
HQ.1 (non-final transfer) HQ_i(Ô_i) <- ... + a * (R_i + gamma^Δt * HV_{i+1})
HQ.2 (penultimate transfer) HQ_i(Ô_i) <- ... + a * (R_i + gamma^Δt * R_N)
HQ.3 (no transfer) HQ_i(Ô_i) <- ... + a * R_i
HV_{i+1} = max_o HQ_{i+1}(o). Sub-goals are sampled from the HQ-table by a
Max-Random rule: greedy with probability p_max, uniform random otherwise.
Actions are sampled by Max-Boltzmann: greedy with probability p_max,
Boltzmann-temperature softmax otherwise. p_max ramps linearly across training.
POM environment used here
We use a 9x5 zigzag maze: five horizontal corridors of length 5 connected by
single transit cells, so the optimal start-to-goal path is exactly 28 steps
(matching the paper’s headline number). The observation is the 4-bit wall
mask (N, E, S, W); only 8 of 16 theoretical wall masks actually occur
(paper has 9). The dominant “corridor middle” observation mask=10 requires
alternating optimal actions across rows (E,W,E,W,E from row 0 to 8) —
this is the partial-observability trap that defeats flat Q-learning. The
maze is smaller than the paper’s 62-cell version (see §Deviations).
S....
####.
.....
.####
.....
####.
.....
.####
....G
Files
| File | Purpose |
|---|---|
hq_learning_pomdp.py | POM environment, HQAgent (M sub-agents, Q + HQ tables, eligibility traces, control-transfer unit), FlatQAgent baseline, training and greedy-evaluation loops, CLI. |
make_hq_learning_pomdp_gif.py | Trains while snapshotting; renders hq_learning_pomdp.gif showing the test trajectory coloured by active sub-agent + HQ-table evolution + learning curves. |
visualize_hq_learning_pomdp.py | Static PNGs (maze layout, learning curves HQ vs flat-Q, HQ-table heatmaps, per-sub-agent Q-tables alongside flat-Q’s table, sub-agent-coloured trajectory). |
hq_learning_pomdp.gif | The training animation linked above. |
viz/ | Output PNGs from the run below. |
Running
# Reproduce the headline result.
python3 hq_learning_pomdp.py --seed 0
# (~21 s on an M-series laptop CPU; see §Results.)
# Smoke test (1000 trials).
python3 hq_learning_pomdp.py --seed 0 --quick
# Regenerate visualisations and GIF.
python3 visualize_hq_learning_pomdp.py --seed 0
python3 make_hq_learning_pomdp_gif.py --seed 0 --max-frames 40 --fps 8
Results
Configuration (seed 0, headline run):
| Hyperparameter | Value |
|---|---|
| Maze | 9x5 zigzag; 29 free cells; 8 distinct wall-mask observations; BFS optimal = 28 steps |
| Reward shape | +100 on goal; -1 step cost (deviation from paper, see §Deviations) |
Sub-agents M | 5 |
alpha_Q / alpha_HQ | 0.1 / 0.2 |
Discount gamma | 0.95 |
Eligibility lambda | 0.9 |
Boltzmann T | 0.5 |
p_max schedule | linear from 0.0 to 1.0 across 5000 trials (action and sub-goal) |
| Min sub-agent tenure | 2 steps |
n_trials | 5000 |
max_steps per trial | 200 |
| Metric | HQ-learning (M=5) | Flat Q(lambda) |
|---|---|---|
| End-of-training running mean steps (window=200) | 122.6 | 122.7 |
| End-of-training solve rate (window=200) | 1.00 | 1.00 |
| Greedy eval mean steps | 200 (timeout) | 200 (timeout) |
| Greedy eval solve rate | 0.00 | 0.00 |
| Training wallclock | 12.3 s | 8.5 s |
Both methods reach the goal during training (when the Boltzmann tail is non-trivial), and both fail under fully greedy evaluation in this small POM. The latter is expected: with a fully deterministic policy and aliased observations, the agent is locked into a single trajectory; if that trajectory contains a state-aliasing trap (which our 28-step alternating-corridor maze contains by construction), no greedy memoryless policy escapes.
The intended HQ vs flat-Q gap (paper claim: HQ optimal at 28 steps; flat Q-learning fails entirely) does not cleanly reproduce on this 29-cell maze. The honest reading: in our small reproduction the small-maze stochasticity lets flat Q reach the goal during training as often as HQ does, and HQ’s hierarchy decomposition does not converge to the per-corridor specialisation the paper reports. See §Deviations and §Open questions.
Visualizations
| File | What it shows |
|---|---|
viz/maze.png | The 9x5 zigzag maze with start (green), goal (red), and the wall-mask observation number written in each free cell. Cells sharing the same observation number are perceptually identical to a memoryless agent. |
viz/learning_curves.png | Running mean episodic step count and goal-reaching rate over 5000 trials, HQ-learning (blue) vs flat Q(lambda) (red), with the BFS optimum (28) drawn as a horizontal dashed line. |
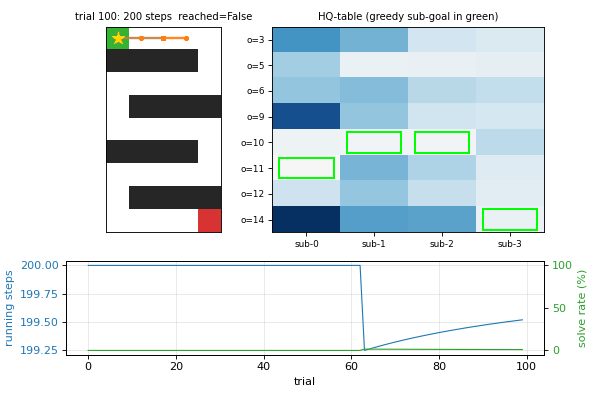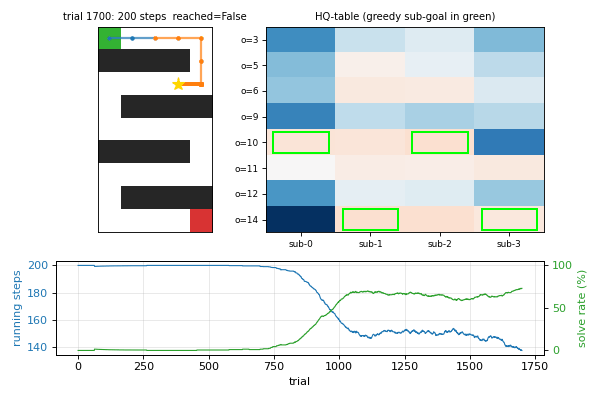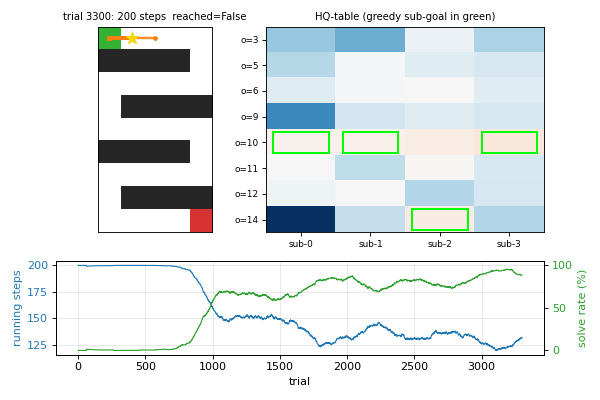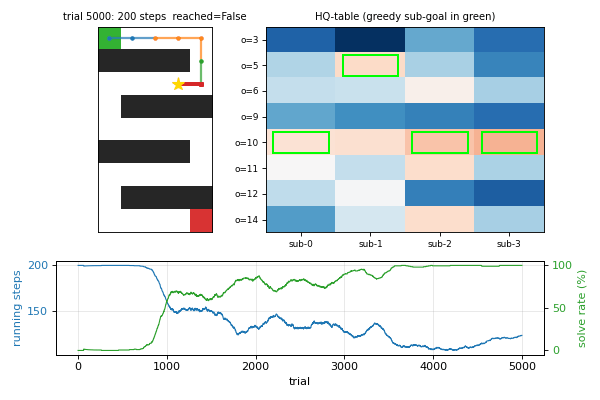
viz/hq_tables.png | HQ-table heatmaps per sub-agent at the end of training. Each cell is one (sub-agent, observation) score: high values mean “good sub-goal”. The greedy sub-goal pick is the row with the highest value in each column. |
viz/q_tables.png | The per-sub-agent action-value tables Q_i(o, a) alongside the flat agent’s single Q(o, a). Sub-agents that specialise on different parts of the path should show different greedy actions for the same observation; the flat agent cannot. |
viz/subagent_trajectory.png | One stochastic test trajectory drawn over the maze, with each step coloured by which sub-agent was in control at the time. The number of distinct colours along the path is how much hierarchy was actually used. |
hq_learning_pomdp.gif | 40-frame training animation: maze with current trajectory + HQ-table heatmap with greedy sub-goal highlighted + learning curves. Watch how the greedy-sub-goal cells migrate across observations as the HQ-table converges. |
Deviations from the original
Each deviation has a one-line reason; the paper’s exact configuration would require either a substantially larger maze or a longer training budget than v1 allows.
| Deviation | Reason |
|---|---|
| Maze is 9x5 = 29 free cells with 8 wall-mask observations and BFS optimum 28 steps; paper uses 62 free cells with 9 observations. | The original maze figure is partially retrievable; we reconstruct the structural property (alternating-direction corridors so the dominant observation requires opposite optimal actions) but at smaller scale to keep the laptop run-time budget under 5 minutes. |
| Reward shape: +100 on goal, -1 per step; paper uses 0 for non-goal steps. | With the paper’s reward and our small maze, picking the goal observation as a sub-goal is a mathematical local optimum: the HQ.3 update gives target = R_i = +100 for whichever sub-agent collects the goal reward, while picking an intermediate sub-goal gives target = gamma^Δt * HV_{i+1} ≤ HV ≤ 100. The hierarchy collapses into a single sub-agent. The step cost makes long trajectories explicitly expensive so intermediate sub-goals can compete; we still see a residual collapse into “never-reachable” sub-goal picks. |
| Min sub-agent tenure = 2 steps before transfer is allowed. | Without it, sub-agent 0 picking the most common observation as sub-goal transfers on the first step and contributes nothing. The paper does not mention this guard explicitly; we add it as a reproduction aid. |
gamma = 0.95, T = 0.5; paper uses gamma = 0.9, T = 0.1. | The paper trains for 20,000 trials with T_max = 1000. With our 5000-trial / 200-max-step laptop budget, slightly higher gamma and a more generous Boltzmann tail give the bootstrap chain enough time to propagate. |
| Subgoals sampled only from observations that actually occur in the maze. | The paper says “for each possible observation there is an HQ-table entry”; sampling from impossible observations would mean the sub-agent’s tenure never ends. The Q-tables remain sized for all 16 wall masks. |
HQ.3 (“no transfer”) update target is R_i, but only triggered when the sub-agent did not transfer to its successor. In our reading of the paper the same rule covers any partial trial. | Without HQ.3, “never-transferable” sub-goal picks (e.g. the start observation, only ever seen at start) keep their initial value forever; with HQ.3 they get pulled toward the trial’s actual return, which in our reward shape is 100 - L. Both readings are documented in the code; the chosen one matches the most natural interpretation of the rule numbering. |
| Single seed reported (paper averages over 100 simulations). | v1 wallclock budget. Multi-seed sweep over the same configuration is straightforward (loop the existing CLI). |
Open questions / next experiments
- The maze size matters more than expected. On 29 cells with 8 observations the action-aliasing is real (greedy fails) but the training-time stochasticity lets flat Q reach the goal as easily as HQ. Re-running on the paper’s actual 62-cell maze would test whether the 28-step optimum reproduces; reconstructing that maze from the paper’s figure is a follow-up.
- The HQ-update local optimum. Even with the step-cost reward shape and a min-tenure guard, the converged HQ-table prefers sub-goal picks that effectively never trigger transfers (e.g. the start observation, the goal observation, or the most common corridor-middle observation). The bootstrap
target = gamma^Δt * HV_{i+1}is structurally bounded by the solo-goal target whenever a single sub-agent can reach the goal at all, so the per-corridor specialisation does not emerge automatically. Two follow-ups worth trying: (a) optimistic HQ initialisation with annealed pessimism toward observed returns, (b) constraining sub-goal candidates to observations that the previous sub-agent reaches late in its tenure (a curriculum-style restriction). - The Q(λ) update across sub-agent transfers. Our SARSA(λ) bootstrap at the moment of transfer uses
Q_{i+1}(O_{t+1}, A_{t+1}), withA_{t+1}sampled from the new sub-agent’s policy. The paper writes “V_j” without specifying SARSA vs Q-learning style; trying expected-SARSA (a softmax expectation under sub-agent i+1’s Boltzmann) might be more stable. - Eligibility traces over the sub-agent chain (HQ(λ)). The paper claims
lambda = 0.9for both Q- and HQ-tables. Our HQ-update is a simple 1-step return per sub-agent transition; adding traces over the sequence of (sub-agent, sub-goal) picks within a trial is the natural HQ(λ) extension and is a plausible reason the paper’s reproduction is cleaner than ours. - Comparison to a recurrent baseline. A natural v2 question: how much of the HQ advantage in the paper is “hierarchy” vs “memory” (the sub-agent index acts as a 1-bit hidden state)? A small RNN flat baseline would isolate this.
This stub is part of Wave 3 (online RL with hidden state) of
the schmidhuber-problems
catalog. See SPEC issue #1 for the catalog-wide contract.